Unified Byte Pair Encoding (BPE) vocabulary. More...
Classes | |
| struct | PairHash |
| struct | PairViewHash |
Public Member Functions | |
| BpeVocabulary ()=delete | |
| const BpeVocabularyConfig & | getConfig () const |
| std::optional< size_t > | getMergePriority (const std::string &left, const std::string &right) const |
| const std::vector< std::pair< std::string, std::string > > & | getMergeRules () const |
| size_t | getSize () const override |
| Get the number of tokens in the vocabulary. | |
| std::optional< TokenId > | getSpecialTokenId (const std::string &token_str) const |
| Look up a special token ID by its string representation. | |
| const std::vector< std::pair< std::string, TokenId > > & | getSpecialTokenList () const |
| Return the special token list sorted longest-first. | |
| std::optional< std::string > | idToToken (TokenId id) const override |
| Map a numeric id back to its token string. | |
| bool | isByteLevel () const |
| void | save (const fs::path &path) const override |
| Serialize the vocabulary to Mila binary format (content version 2). | |
| std::optional< TokenId > | tokenToId (const std::string &token) const override |
| Convert a token string to its ID. | |
| Public Member Functions inherited from Mila::Data::TokenizerVocabulary | |
| virtual | ~TokenizerVocabulary ()=default |
| Virtual destructor. | |
| virtual void | save (const std::filesystem::path &path) const =0 |
| Serialize the vocabulary to disk at the given path. | |
Static Public Member Functions | |
| static const std::unordered_map< std::string, unsigned char > & | getByteDecoder () |
| static const std::unordered_map< unsigned char, std::string > & | getByteEncoder () |
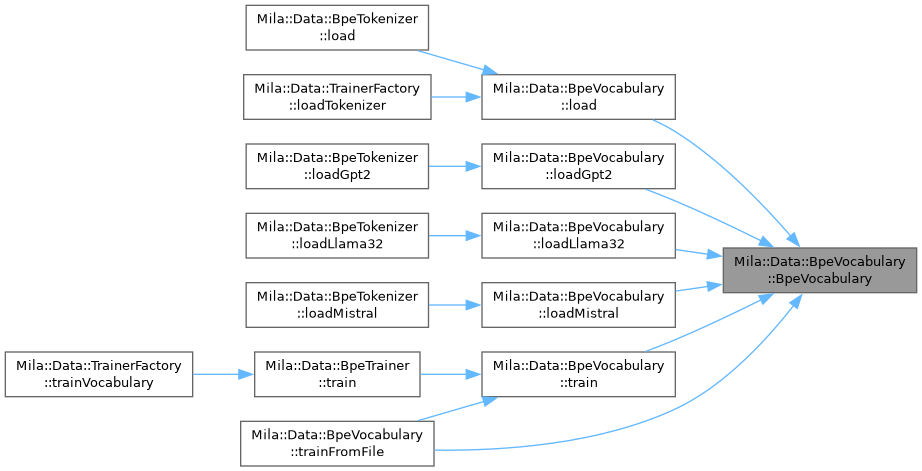
| static BpeVocabulary | load (const fs::path &path) |
| Load a vocabulary from Mila binary format (version 2). | |
| static BpeVocabulary | loadGpt2 (const fs::path &tokenizer_path) |
| Load a pretrained GPT-2 vocabulary. | |
| static BpeVocabulary | loadLlama32 (const fs::path &path) |
| Load a pretrained Llama 3.2 vocabulary. | |
| static BpeVocabulary | loadMistral (const fs::path &vocab_path, const fs::path &merges_path) |
| Load a pretrained Mistral vocabulary. | |
| static BpeVocabulary | train (const std::string &corpus, const BpeVocabularyConfig &config) |
| Train a BPE vocabulary from a text corpus. | |
| static BpeVocabulary | trainFromFile (const fs::path &corpus_path, const BpeVocabularyConfig &config) |
| Train a BPE vocabulary from a corpus file. | |
Private Member Functions | |
| BpeVocabulary (const BpeVocabularyConfig &config) | |
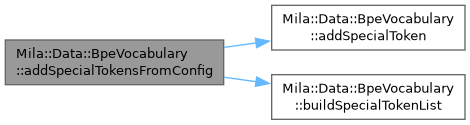
| void | addSpecialToken (const std::string &token, TokenId id) |
| void | addSpecialTokensFromConfig () |
| void | applyMergeAndUpdateCounts (std::vector< std::vector< std::string > > &corpus, const std::string &left, const std::string &right, const std::string &merged, std::unordered_map< std::pair< std::string, std::string >, size_t, PairHash > &pair_counts) |
| void | buildFromText (const std::string &corpus) |
| void | buildMergeMap () |
| void | buildSpecialTokenList () |
| std::vector< std::vector< std::string > > | convertToTokenSequences (const std::vector< std::string > &words) |
| std::unordered_map< std::pair< std::string, std::string >, size_t, PairHash > | countPairs (const std::vector< std::vector< std::string > > &corpus) const |
| std::pair< std::pair< std::string, std::string >, size_t > | getMostFrequentPair (const std::unordered_map< std::pair< std::string, std::string >, size_t, PairHash > &counts) const |
| void | initializeBaseVocabulary () |
| void | loadContent (std::istream &file) |
| void | logTrainingComplete (std::chrono::steady_clock::time_point start_time) |
| std::vector< std::string > | preTokenize (const std::string &text) const |
| std::vector< std::string > | preTokenizeCorpus (const std::string &text) |
| void | runBpeMergeLoop (std::vector< std::vector< std::string > > &corpus_tokens, std::chrono::steady_clock::time_point start_time) |
| void | saveContent (std::ostream &file) const |
Private Attributes | |
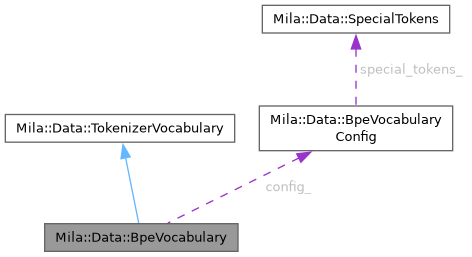
| BpeVocabularyConfig | config_ |
| TokenId | current_id_ |
| std::vector< std::string > | id_to_token_ |
| std::unordered_map< std::pair< std::string, std::string >, size_t, PairHash > | merge_map_ |
| std::vector< std::pair< std::string, std::string > > | merges_ |
| std::unordered_map< std::string, TokenId > | special_token_ids_ |
| std::vector< std::pair< std::string, TokenId > > | special_token_list_ |
| std::unordered_map< std::string, TokenId > | token_to_id_ |
Detailed Description
Unified Byte Pair Encoding (BPE) vocabulary.
Immutable after construction; safe for concurrent reads. Supports training from scratch via BpeTrainer, or loading pretrained vocabularies from:
- Mila binary format produced by save() (load)
- GPT-2 binary produced by convert_gpt2_tokenizer.py (loadGpt2)
- Llama 3.2 binary produced by convert_llama_tokenizer.py (loadLlama32)
Special tokens are keyed on their string representation (e.g., "<|endoftext|>", "<|begin_of_text|>") and exposed via getSpecialTokenList() for O(n) pre-pass scanning in BpeTokenizer. Extended special tokens from SpecialTokens are registered automatically.
Constructor & Destructor Documentation
◆ BpeVocabulary() [1/2]
|
delete |
◆ BpeVocabulary() [2/2]
|
inlineexplicitprivate |
Member Function Documentation
◆ addSpecialToken()
|
private |

◆ addSpecialTokensFromConfig()
|
private |

◆ applyMergeAndUpdateCounts()
|
private |

◆ buildFromText()
|
private |

◆ buildMergeMap()
|
private |
◆ buildSpecialTokenList()
|
private |
◆ convertToTokenSequences()
|
private |

◆ countPairs()
|
private |

◆ getByteDecoder()
|
static |


◆ getByteEncoder()
|
static |
◆ getConfig()
|
inline |
◆ getMergePriority()
|
inline |
◆ getMergeRules()
|
inline |
◆ getMostFrequentPair()
|
private |

◆ getSize()
|
inlineoverridevirtual |
Get the number of tokens in the vocabulary.
- Returns
- size_t Number of entries (tokens) present in the vocabulary.
Implements Mila::Data::TokenizerVocabulary.
◆ getSpecialTokenId()
|
inline |
Look up a special token ID by its string representation.
Used by BpeTokenizer's encode pre-pass to resolve tokens such as "<|endoftext|>" or "<|begin_of_text|>" directly to IDs before BPE runs.
- Parameters
-
token_str Token string to look up.
- Returns
- Token ID if registered as special, nullopt otherwise.
◆ getSpecialTokenList()
|
inline |
Return the special token list sorted longest-first.
Ordered longest-first so BpeTokenizer's linear scan matches longer tokens before any of their prefixes (e.g., "<|begin_of_text|>" before "<|").
- Returns
- Vector of (token_string, token_id) pairs.
◆ idToToken()
|
inlineoverridevirtual |
Map a numeric id back to its token string.
Returns an empty optional if the id is out of range or not defined.
- Parameters
-
id Token id to convert.
- Returns
- std::optional<std::string> The token string if present, otherwise empty.
Implements Mila::Data::TokenizerVocabulary.
◆ initializeBaseVocabulary()
|
private |

◆ isByteLevel()
|
inline |
◆ load()
|
inlinestatic |
Load a vocabulary from Mila binary format (version 2).
Reads a file written by save(). Special tokens are restored from the serialized (string, id) pairs and the special token list is rebuilt automatically.
- Parameters
-
path Input file path.
- Returns
- Loaded BpeVocabulary instance.
- Exceptions
-
std::runtime_error on I/O errors or format mismatch.
◆ loadContent()
|
private |

◆ loadGpt2()
|
static |
Load a pretrained GPT-2 vocabulary.
Reads the binary format produced by convert_gpt2_tokenizer.py:
- Parameters
-
tokenizer_path Path to the converted GPT-2 tokenizer binary.
- Returns
- Loaded BpeVocabulary instance.
- Exceptions
-
std::runtime_error on I/O or format errors.

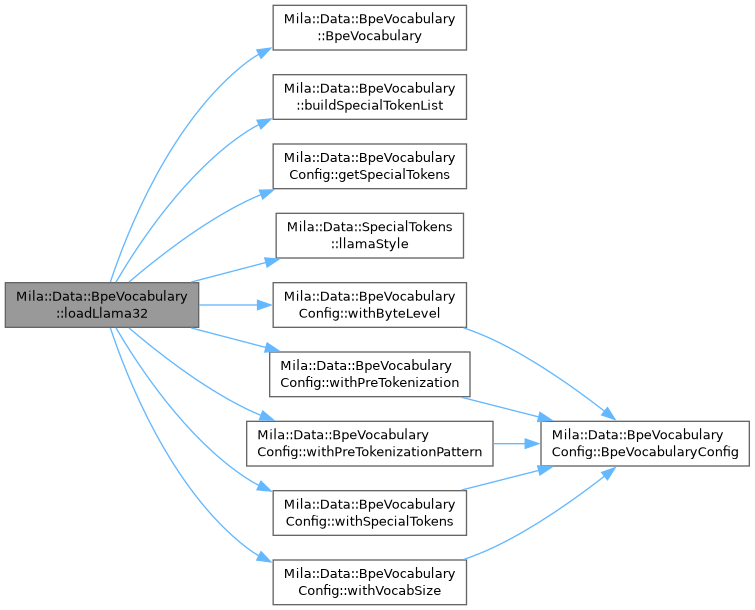
◆ loadLlama32()
|
static |
Load a pretrained Llama 3.2 vocabulary.
Reads the binary format produced by convert_llama_tokenizer.py:
Llama 3.x vocabularies carry no explicit BPE merges; the merge order is encoded implicitly in the token ID assignment.
- Parameters
-
path Path to the converted Llama 3.2 tokenizer binary.
- Returns
- Loaded BpeVocabulary instance.
- Exceptions
-
std::runtime_error on I/O or format errors.

◆ loadMistral()
|
static |


◆ logTrainingComplete()
|
private |

◆ preTokenize()
|
private |

◆ preTokenizeCorpus()
|
private |


◆ runBpeMergeLoop()
|
private |

◆ save()
|
inlineoverride |
Serialize the vocabulary to Mila binary format (content version 2).
Writes a MilaFileHeader followed by the vocabulary content. Special tokens are stored as (string_length, string, token_id) triples, eliminating the char-key indirection used in the former GPT-2-only format.
- Parameters
-
path Output file path. Parent directory must exist.
- Exceptions
-
std::runtime_error on I/O errors.


◆ saveContent()
|
private |

◆ tokenToId()
|
inlineoverridevirtual |
Convert a token string to its ID.
Falls back to the UNK token ID when the token is not found and use_unk is enabled (GPT-2 style). Llama 3.x vocabularies return nullopt on a miss because they rely on byte-level fallback rather than an UNK token.
- Parameters
-
token UTF-8 encoded token string.
- Returns
- Token ID, UNK ID (if enabled), or nullopt on miss.
Implements Mila::Data::TokenizerVocabulary.
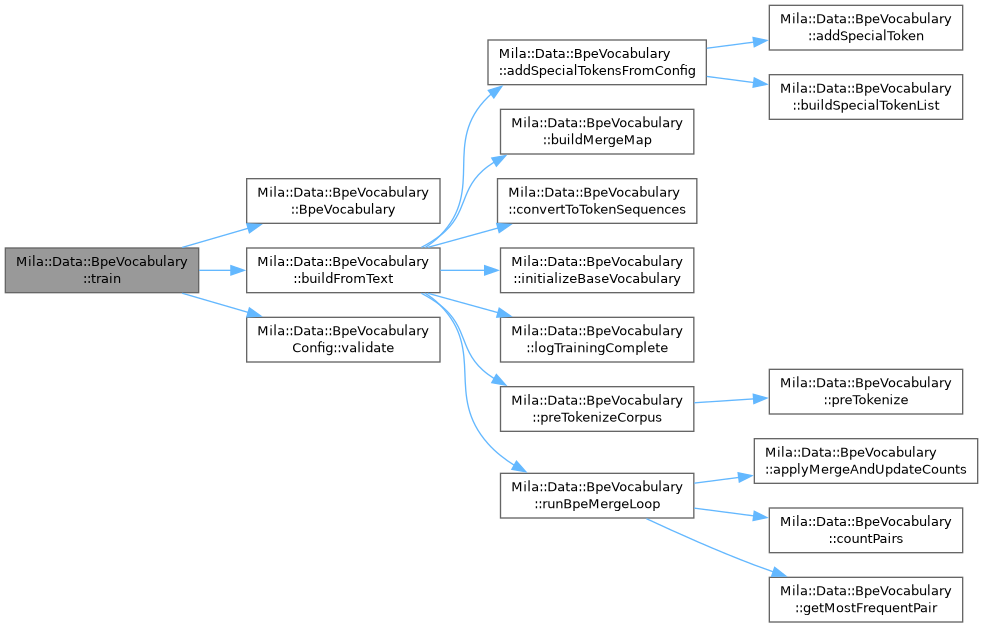
◆ train()
|
inlinestatic |
Train a BPE vocabulary from a text corpus.
- Parameters
-
corpus Training text. config Vocabulary configuration; config.validate() is called internally.
- Returns
- Trained BpeVocabulary instance.
- Exceptions
-
std::invalid_argument if config fails validation.

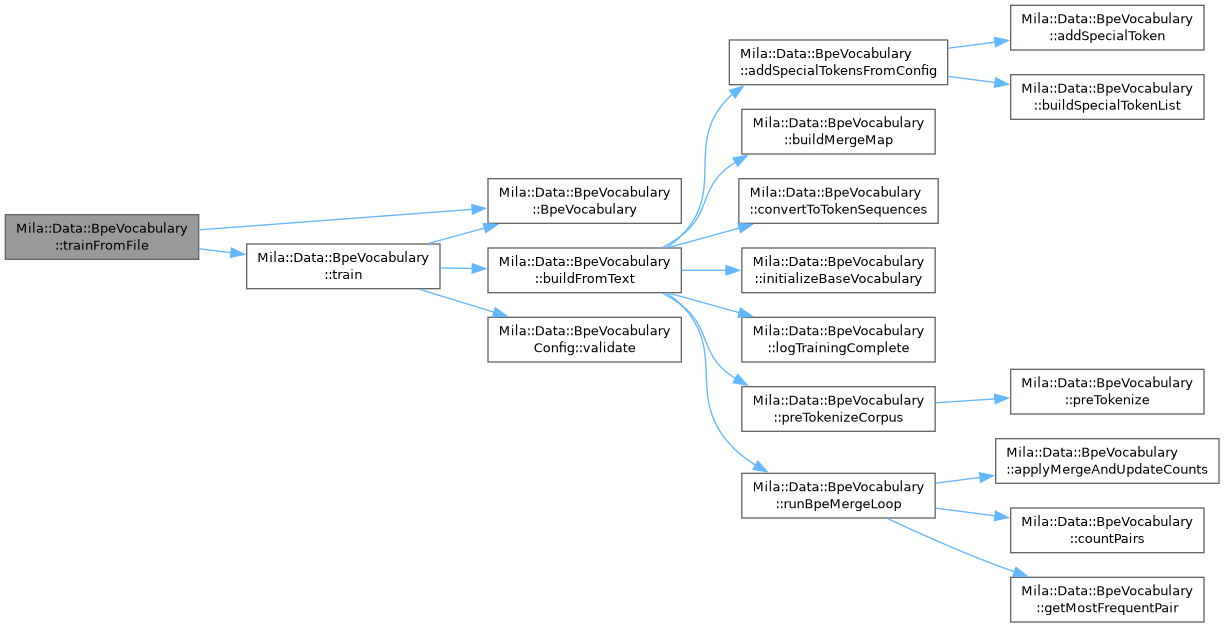
◆ trainFromFile()
|
inlinestatic |
Train a BPE vocabulary from a corpus file.
- Parameters
-
corpus_path Path to a UTF-8 text corpus file. config Vocabulary configuration.
- Returns
- Trained BpeVocabulary instance.
- Exceptions
-
std::runtime_error if the file cannot be opened. std::invalid_argument if config fails validation.
Member Data Documentation
◆ config_
|
private |
◆ current_id_
|
private |
◆ id_to_token_
|
private |
◆ merge_map_
|
private |
◆ merges_
|
private |
◆ special_token_ids_
|
private |
◆ special_token_list_
|
private |
◆ token_to_id_
|
private |
The documentation for this class was generated from the following file:
- /__w/Mila/Mila/Mila/Src/Data/Tokenizers/Bpe/BpeVocabulary.ixx