|
| template<DeviceType TDeviceType, TensorDataType TInputA, TensorDataType TInputB = TInputA, TensorDataType TComputePrecision = TInputA> |
| std::shared_ptr< BinaryOperation< TDeviceType, TInputA, TInputB, TComputePrecision > > | createBinaryOperation (const std::string &operation_name, IExecutionContext *context, const ComponentConfig &config) const |
| | Create a binary operation instance.
|
| template<DeviceType TDeviceType, TensorDataType TPrecision, TensorDataType TInputA = TPrecision, TensorDataType TInputB = TInputA> |
| std::shared_ptr< PairedOperation< TDeviceType, TPrecision, TInputA, TInputB > > | createPairedOperation (const std::string &operation_name, IExecutionContext *context, const ComponentConfig &config) const |
| | Create a paired operation instance.
|
| template<DeviceType TDeviceType, TensorDataType TInputType, TensorDataType TComputePrecision = TInputType> |
| std::shared_ptr< UnaryOperation< TDeviceType, TInputType, TComputePrecision > > | createUnaryOperation (const std::string &operation_name, IExecutionContext *context, const ComponentConfig &config) const |
| | Create a unary operation instance.
|
| template<DeviceType TDeviceType, TensorDataType TInputA, TensorDataType TInputB = TInputA, TensorDataType TComputePrecision = TInputA> |
| std::vector< std::string > | getRegisteredOperations () const |
| | Return all registered operation names across all arities for a given type configuration.
|
| template<DeviceType TDeviceType, TensorDataType TInputA, TensorDataType TInputB = TInputA, TensorDataType TComputePrecision = TInputA> |
| bool | isOperationRegistered (const std::string &operation_name) const |
| | Return true if an operation name is registered under any arity for a given type configuration.
|
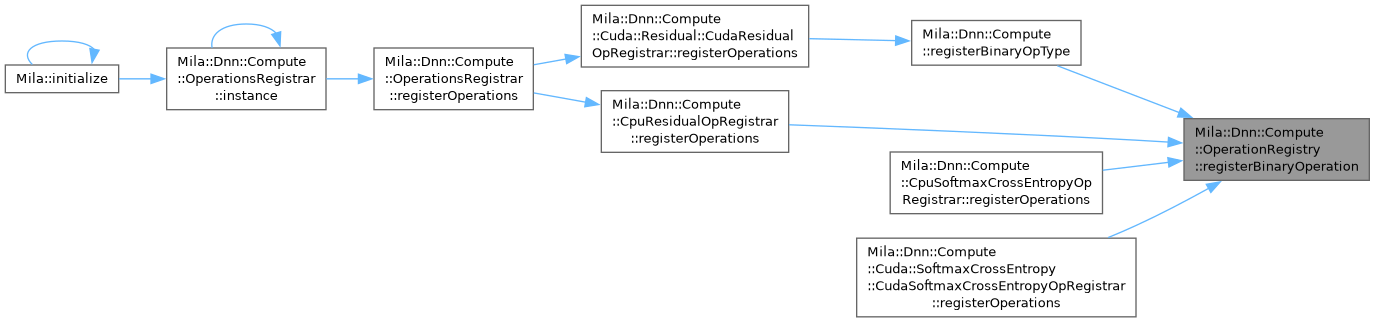
| template<DeviceType TDeviceType, TensorDataType TInputA, TensorDataType TInputB = TInputA, TensorDataType TComputePrecision = TInputA> |
| void | registerBinaryOperation (const std::string &operation_name, std::function< std::shared_ptr< BinaryOperation< TDeviceType, TInputA, TInputB, TComputePrecision > >(IExecutionContext *, const ComponentConfig &)> creator) |
| | Register a binary operation factory.
|
| template<DeviceType TDeviceType, TensorDataType TPrecision, TensorDataType TInputA = TPrecision, TensorDataType TInputB = TInputA> |
| void | registerPairedOperation (const std::string &operation_name, std::function< std::shared_ptr< PairedOperation< TDeviceType, TPrecision, TInputA, TInputB > >(IExecutionContext *, const ComponentConfig &)> creator) |
| | Register a paired operation factory.
|
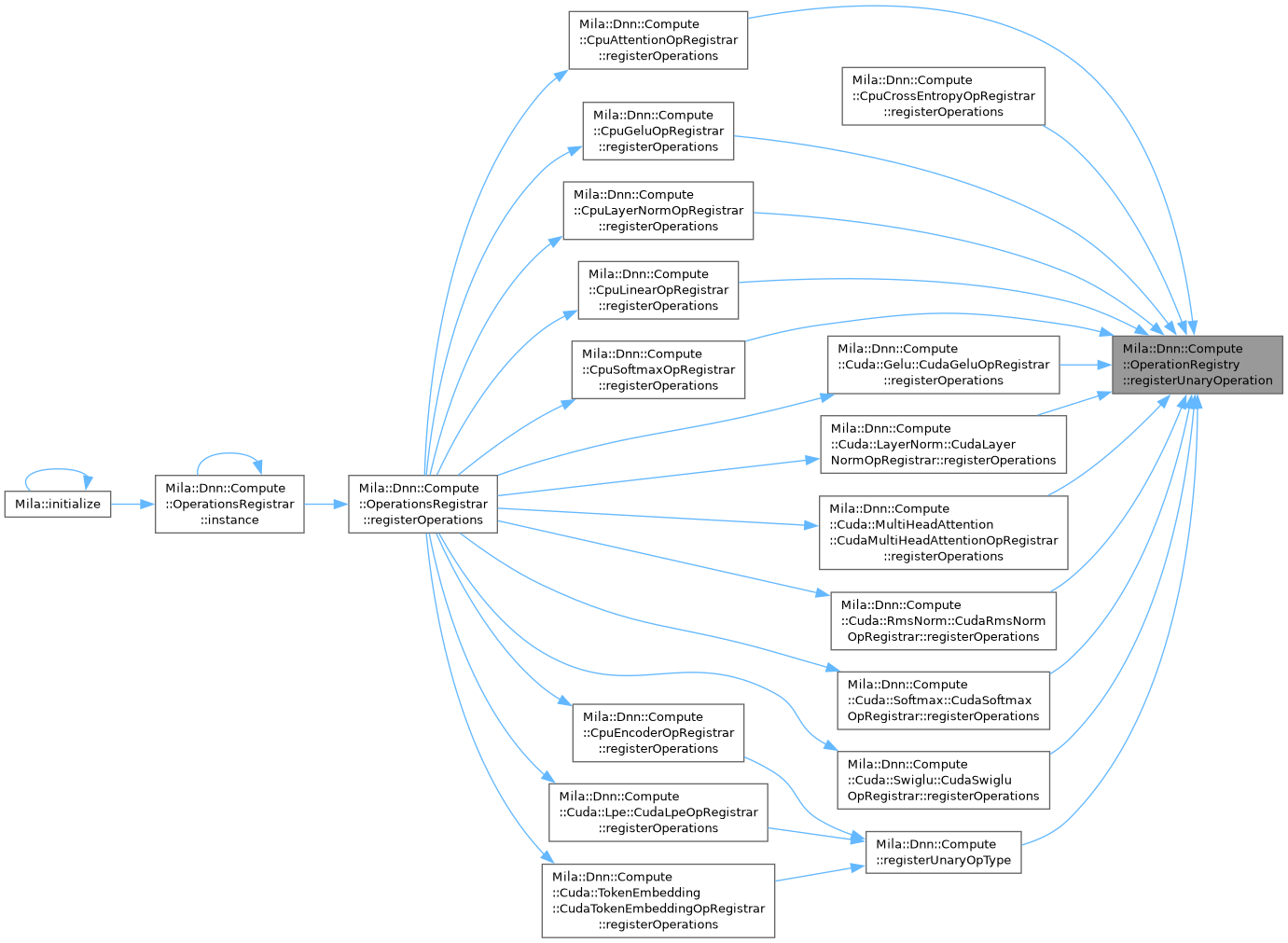
| template<DeviceType TDeviceType, TensorDataType TInputType, TensorDataType TComputePrecision = TInputType> |
| void | registerUnaryOperation (std::string_view operation_name, std::function< std::shared_ptr< UnaryOperation< TDeviceType, TInputType, TComputePrecision > >(IExecutionContext *, const ComponentConfig &)> creator) |
| | Register a unary operation factory.
|
Central registry for typed, device-aware compute operations.
Maintains three independent stores keyed by (DeviceType, input types, compute precision) and operation name — one per operation arity. Separation prevents cross-arity static_pointer_cast UB when an op is retrieved under the wrong base type.