|
| struct | always_false |
| class | BinaryOperation |
| class | CpuAdamWOptimizer |
| | CPU-specific AdamW optimizer implementation. More...
|
| class | CpuAttentionOp |
| | CPU implementation of Multi-Head Attention operation. More...
|
| class | CpuAttentionOpRegistrar |
| class | CpuCrossEntropyOp |
| | CPU implementation of the cross entropy loss operation for neural networks. More...
|
| class | CpuCrossEntropyOpRegistrar |
| | Class responsible for registering the CpuCrossEntropyOp operation. More...
|
| class | CpuDevice |
| | Class representing a CPU compute device. More...
|
| class | CpuDeviceRegistrar |
| | CPU device plugin for device-agnostic registration. More...
|
| class | CpuEncoderOp |
| | CPU implementation of the Encoder operation. More...
|
| class | CpuEncoderOpRegistrar |
| | Registrar for CpuEncoderOp operation. More...
|
| class | CpuGeluOp |
| | CPU implementation of GELU activation operation using abstract TensorDataType. More...
|
| class | CpuGeluOpRegistrar |
| | Class responsible for registering CPU GELU operations. More...
|
| class | CpuLayerNormOp |
| | CPU implementation of Layer Normalization using abstract TensorDataType API. More...
|
| class | CpuLayerNormOpRegistrar |
| class | CpuLinearOp |
| | CPU implementation of Linear operation using abstract TensorDataType API. More...
|
| class | CpuLinearOpRegistrar |
| class | CpuMemoryResource |
| | CPU memory resource for host-accessible memory allocation. More...
|
| class | CpuResidualOp |
| | CPU Residual operation (FP32) implementing BinaryOperation interface. More...
|
| class | CpuResidualOpRegistrar |
| | Registrar for CPU Residual operation (FP32). More...
|
| class | CpuSoftmaxCrossEntropyOp |
| | Fused CPU implementation of Softmax + CrossEntropy using abstract TensorDataType API. More...
|
| class | CpuSoftmaxCrossEntropyOpRegistrar |
| | Registrar for fused Softmax+CrossEntropy operation. More...
|
| class | CpuSoftmaxOp |
| | CPU implementation of Softmax using abstract TensorDataType API. More...
|
| class | CpuSoftmaxOpRegistrar |
| class | CublasLtError |
| class | CudaAdamWOptimizer |
| | CUDA-specific AdamW optimizer implementation. More...
|
| class | CudaBadAlloc |
| struct | CudaDataTypeMap |
| | Helper struct to map C++ types to CUDA data types for cuBLASLt. More...
|
| struct | CudaDataTypeMap< __nv_bfloat16 > |
| struct | CudaDataTypeMap< float > |
| struct | CudaDataTypeMap< half > |
| class | CudaDevice |
| | Class representing a CUDA compute device instance. More...
|
| class | CudaDeviceMemoryResource |
| | CUDA device memory resource for GPU-accessible memory allocation. More...
|
| class | CudaDeviceProps |
| | Wrapper for CUDA device properties with cached values. More...
|
| class | CudaDeviceRegistrar |
| | CUDA device registrar for device-agnostic registration. More...
|
| class | CudaError |
| | Exception class for CUDA runtime errors. More...
|
| class | CudaManagedMemoryResource |
| | CUDA managed memory resource for unified host/device accessible memory. More...
|
| class | CudaPinnedMemoryResource |
| | CUDA pinned memory resource for fast host/device transfer memory. More...
|
| class | CudaTimer |
| | GPU-accurate interval timer using a CUDA event pair. More...
|
| class | Device |
| | Abstract interface for compute device implementations. More...
|
| struct | DeviceAccessible |
| class | DeviceConstructionKey |
| | Construction key for device factories. More...
|
| struct | DeviceId |
| | Lightweight identifier for a compute device. More...
|
| class | DeviceRegistrar |
| | Device-agnostic registrar for automatic device discovery and registration. More...
|
| class | DeviceRegistry |
| | Registry of discovered compute devices with lazy instantiation. More...
|
| struct | DeviceTypeTraits |
| struct | DeviceTypeTraits< DeviceType::Cpu > |
| | DeviceTypeTraits specialization for the CPU device. More...
|
| struct | DeviceTypeTraits< DeviceType::Cuda > |
| | DeviceTypeTraits specialization for the CUDA device. More...
|
| class | ExecutionContext |
| | Templated execution context for device-specific operations. More...
|
| class | ExecutionContext< DeviceType::Cpu > |
| | CPU execution context specialization. More...
|
| class | ExecutionContext< DeviceType::Cuda > |
| | CUDA execution context specialization. More...
|
| class | ExecutionContext< DeviceType::Metal > |
| | Metal execution context specialization. More...
|
| class | ExecutionContext< DeviceType::Vulkan > |
| | Vulkan execution context specialization. More...
|
| struct | GqaState |
| | Non-owning pointers to shared transient GQA scratch buffers. More...
|
| struct | HostAccessible |
| class | IExecutionContext |
| | Type-erased execution context interface. More...
|
| struct | IKvCacheLifecycle |
| | Capability interface for KV-cache state management. More...
|
| struct | IKvInference |
| | Compute interface for attention operations that maintain a KV cache. More...
|
| struct | IPackedKvInference |
| | KV-cache inference interface for packed-QKV MHA backends. More...
|
| struct | IPositionalDecode |
| | Capability interface for position-dependent unary operations. More...
|
| struct | IPositionalPairedOp |
| | Capability interface for position-dependent paired operations. More...
|
| struct | LinearOpTypeMap< DeviceType::Cpu, TensorDataType::FP32 > |
| class | MemoryResource |
| | Clean memory resource abstraction for device-specific memory allocation. More...
|
| struct | MemoryResourceTraits |
| | Memory resource traits for compile-time dispatch optimization. More...
|
| struct | MemoryResourceTraits< CpuMemoryResource > |
| | CPU-specific memory resource traits providing detailed CPU backend characteristics. More...
|
| struct | MemoryResourceTraits< CudaDeviceMemoryResource > |
| | CUDA device memory resource traits providing detailed GPU backend characteristics. More...
|
| struct | MemoryResourceTraits< CudaManagedMemoryResource > |
| | CUDA managed memory resource traits providing unified memory characteristics. More...
|
| struct | MemoryResourceTraits< CudaPinnedMemoryResource > |
| | CUDA pinned memory resource traits providing fast transfer characteristics. More...
|
| struct | MemoryStats |
| | Global memory statistics for all TrackedMemoryResource instances. More...
|
| class | MetalDevice |
| | Class representing a Metal compute device instance. More...
|
| class | MetalDevicePlugin |
| | Metal device plugin for device-agnostic registration. More...
|
| class | MetalMemoryResource |
| | Stub implementation for non-Apple platforms. More...
|
| class | Operation |
| class | OperationRegistry |
| | Central registry for typed, device-aware compute operations. More...
|
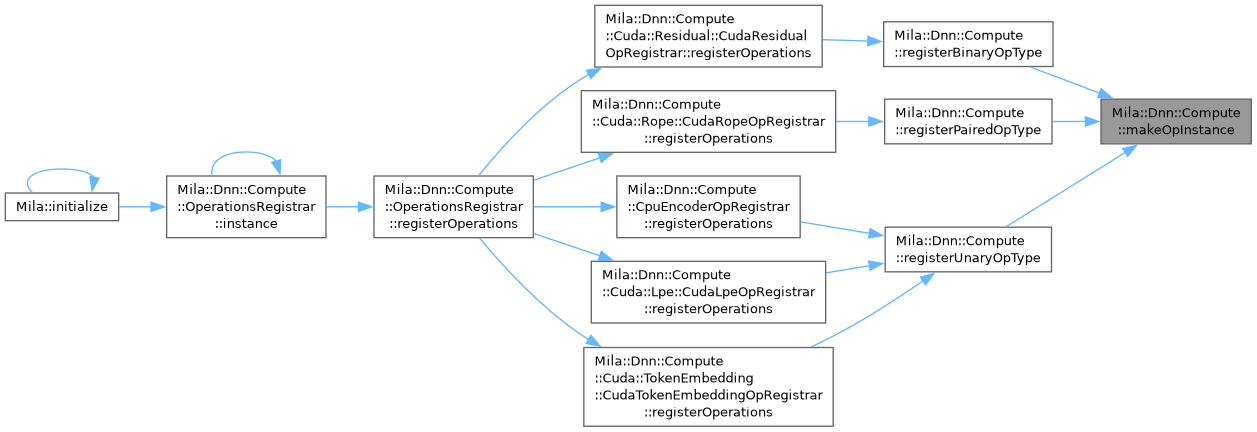
| class | OperationsRegistrar |
| | Class to manage compute operations initialization. More...
|
| struct | OperationTraits |
| | Primary traits template for unified compile-time operation dispatch. More...
|
| struct | OperationTraits< OperationType::CrossEntropyOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::CrossEntropyOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::GeluOp, DeviceType::Cpu, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::GeluOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::GeluOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::GroupedQueryAttentionOp, DeviceType::Cuda, TensorDataType::BF16, NoKvCompression > |
| | Unquantized BF16 path. No KV cache compression. Standard inference precision. More...
|
| struct | OperationTraits< OperationType::GroupedQueryAttentionOp, DeviceType::Cuda, TensorDataType::FP32, NoKvCompression > |
| | Unquantized FP32 path. No KV cache compression. More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cpu, TensorDataType::FP32, NoWeightQuant > |
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::BF16, NoWeightQuant > |
| | Unquantized BF16 path. Standard inference precision. More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::BF16, PerChannelFp8<> > |
| | FP8 per-channel quantized BF16 path. Requires SM >= 8.0 (Ampere+). More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::BF16, PerGroupFp4< 128 > > |
| | FP4 E2M1 per-group quantized BF16 path. W4A16 fused GEMM with E2M1 decode, group_size=128. Requires SM >= 8.0. More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::BF16, PerGroupFp4< 64 > > |
| | FP4 E2M1 per-group quantized BF16 path. W4A16 fused GEMM with E2M1 decode, group_size=64. Requires SM >= 8.0. More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::BF16, PerGroupInt4< 128 > > |
| | INT4 per-group quantized BF16 path. W4A16 fused GEMM, group_size=128. Requires SM >= 8.0. More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::BF16, PerGroupInt4< 64 > > |
| | INT4 per-group quantized BF16 path. W4A16 fused GEMM, group_size=64. Requires SM >= 8.0. More...
|
| struct | OperationTraits< OperationType::LinearOp, DeviceType::Cuda, TensorDataType::FP32, NoWeightQuant > |
| | Unquantized FP32 path. Retained for validation and reference. More...
|
| struct | OperationTraits< OperationType::LpeOp, DeviceType::Cpu, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::LpeOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::LpeOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::MultiHeadAttentionOp, DeviceType::Cpu, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::MultiHeadAttentionOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::MultiHeadAttentionOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::ResidualOp, DeviceType::Cpu, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::ResidualOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::ResidualOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::RmsNormOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::RmsNormOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::RopeOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::RopeOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::SoftmaxOp, DeviceType::Cpu, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::SoftmaxOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::SoftmaxOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::SwigluOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::SwigluOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| struct | OperationTraits< OperationType::TokenEmbeddingOp, DeviceType::Cuda, TensorDataType::BF16, void > |
| struct | OperationTraits< OperationType::TokenEmbeddingOp, DeviceType::Cuda, TensorDataType::FP32, void > |
| class | Optimizer |
| | Abstract base class for parameter optimizers. More...
|
| class | PairedOperation |
| | Abstract base for paired operations: two inputs -> two outputs. More...
|
| class | TrackedMemoryResource |
| | A memory resource wrapper that tracks allocation and deallocation statistics. More...
|
| class | UnaryOperation |
| class | VulkanDevice |
| | Class representing a Vulkan compute device instance. More...
|
| class | VulkanMemoryResource |
| | Stub implementation for platforms without Vulkan support. More...
|
|
| template<typename Tp, typename Tg> |
| void | adamw_update (Tp *params_memory, float *master_params_memory, Tg *grads_memory, float *m_memory, float *v_memory, size_t num_parameters, ptrdiff_t w_stride, ptrdiff_t g_stride, ptrdiff_t s_stride, int num_slices, float learning_rate, float beta1, float beta2, int t, float eps, float weight_decay, float grad_scale, unsigned int seed, cudaStream_t stream) |
| template<DeviceType TDeviceType> |
| const ExecutionContext< TDeviceType > * | Mila::Dnn::Compute::cast_context_ (const IExecutionContext *ctx) noexcept |
| template<DeviceType TDeviceType> |
| ExecutionContext< TDeviceType > * | Mila::Dnn::Compute::cast_context_ (IExecutionContext *ctx) noexcept |
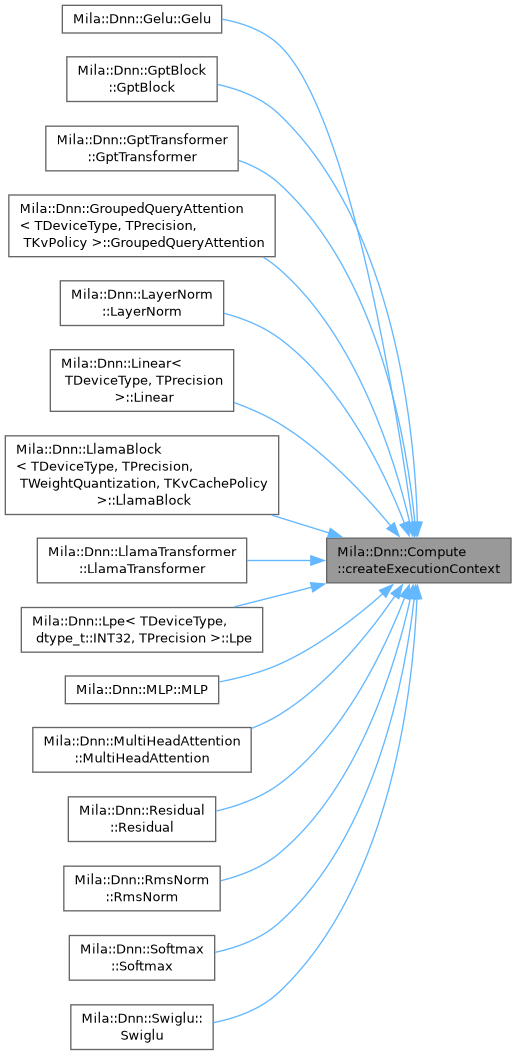
| std::unique_ptr< IExecutionContext > | Mila::Dnn::Compute::createExecutionContext (DeviceId device_id) |
| | Create execution context for specified device.
|
| void | Mila::Dnn::Compute::cublasLtCheckStatus (cublasStatus_t status, const std::source_location &location=std::source_location::current()) |
| | Checks the status of a cuBLASLt operation and throws if an error occurred.
|
| void | cuda_mha_forward_fp16 (half *Y, half *qkvr, half *att, const half *X, int B, int T, int C, int NH, cudaStream_t stream) |
| void | cuda_mha_forward_fp32 (float *Y, float *qkvr, float *att, const float *X, int B, int T, int C, int NH, cudaStream_t stream) |
| template<typename TPrecision> |
| void | cuda_softmax_crossentropy_backward (TPrecision *dX, const TPrecision *dY_loss, const TPrecision *Y, const int *targets, int batch_size, int seq_len, int vocab_size, cudaStream_t stream) |
| template<typename TPrecision> |
| void | cuda_softmax_crossentropy_forward (TPrecision *Y_loss, TPrecision *Y, const TPrecision *X, const int *targets, int batch_size, int seq_len, int vocab_size, cudaStream_t stream) |
| void | Mila::Dnn::Compute::cudaCheckLastError (const std::source_location &location=std::source_location::current()) |
| | Checks the last CUDA error and throws if an error occurred.
|
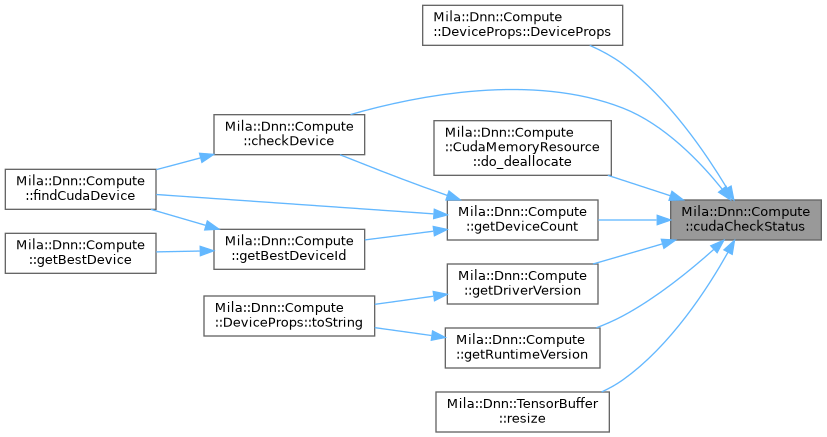
| void | Mila::Dnn::Compute::cudaCheckStatus (cudaError_t status, const std::source_location &location=std::source_location::current()) |
| | Checks the status of a CUDA operation and throws if an error occurred.
|
| std::string | Mila::Dnn::Compute::deviceTypeToString (DeviceType device_type) |
| | Converts a DeviceType to its string representation.
|
| DeviceId | Mila::Dnn::Compute::getBestDevice (DeviceType type, bool preferMemory=false) |
| | Gets the best DeviceId of a specific type based on performance characteristics.
|
| std::size_t | Mila::Dnn::Compute::getDeviceCount (DeviceType type) noexcept |
| | Count instantiated devices of the given DeviceType.
|
| template<DeviceType TDevice, TensorDataType TDataType> |
| std::vector< std::string > | Mila::Dnn::Compute::getRegisteredOperations () |
| | Templated helper returning registered operation names for a compile-time device and tensor data type.
|
| template<DeviceType TDevice, TensorDataType TDataType> |
| bool | Mila::Dnn::Compute::isOperationRegistered (const std::string &operation_name) |
| | Templated helper that checks whether a named operation is registered for a compile-time device and tensor data type.
|
| std::vector< std::string > | Mila::Dnn::Compute::listDevicesByName () |
| | Lists all available compute devices by name.
|
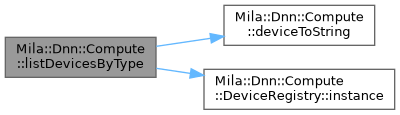
| std::vector< std::string > | Mila::Dnn::Compute::listDevicesByType (DeviceType type) |
| | Lists compute devices of a specific type.
|
| template<typename OpType, DeviceType DT, typename ConfigT> |
| std::shared_ptr< OpType > | makeOpInstance (IExecutionContext *ctx, const ConfigT &cfg) |
| | Attempt to construct an OpType instance from a raw IExecutionContext*.
|
| std::string_view | Mila::Dnn::Compute::operationTypeToString (OperationType op) |
| template<DeviceType TDataType, typename OpType, Dnn::TensorDataType TA, Dnn::TensorDataType TB, Dnn::TensorDataType TP = TA> |
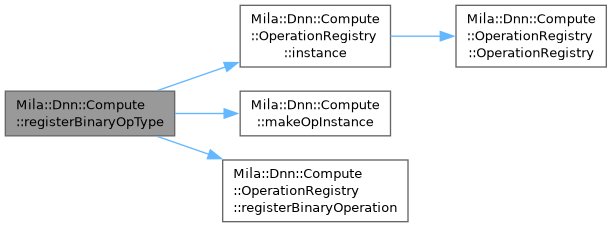
| void | Mila::Dnn::Compute::registerBinaryOpType (const std::string &opName) |
| | Register a binary operation type with OperationRegistry using a common factory pattern.
|
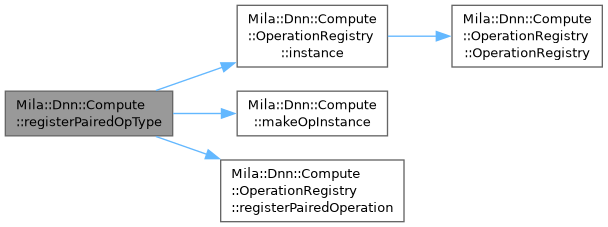
| template<DeviceType TDataType, typename OpType, Dnn::TensorDataType TA, Dnn::TensorDataType TB = TA, Dnn::TensorDataType TP = TA> |
| void | Mila::Dnn::Compute::registerPairedOpType (const std::string &opName) |
| | Register a paired operation type with OperationRegistry using a common factory pattern.
|
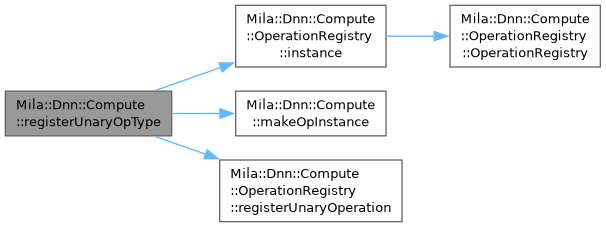
| template<DeviceType TDataType, typename OpType, Dnn::TensorDataType TInput, Dnn::TensorDataType TPrecision = TInput> |
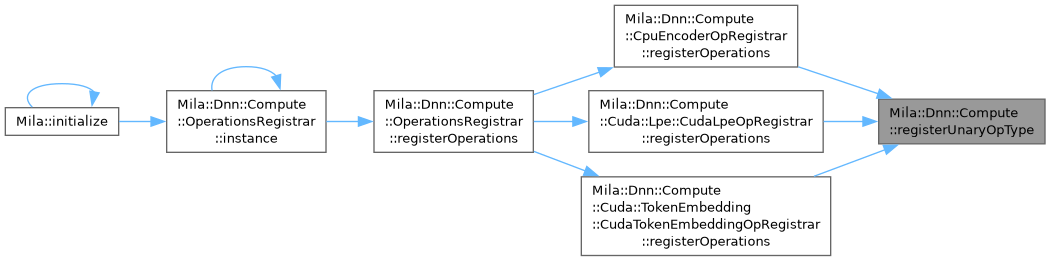
| void | Mila::Dnn::Compute::registerUnaryOpType (std::string_view op_name) |
| | Register a unary operation type with OperationRegistry using a common factory pattern.
|
| DeviceType | Mila::Dnn::Compute::toDeviceType (std::string_view device_type) |
| | Converts a string to the corresponding DeviceType.
|
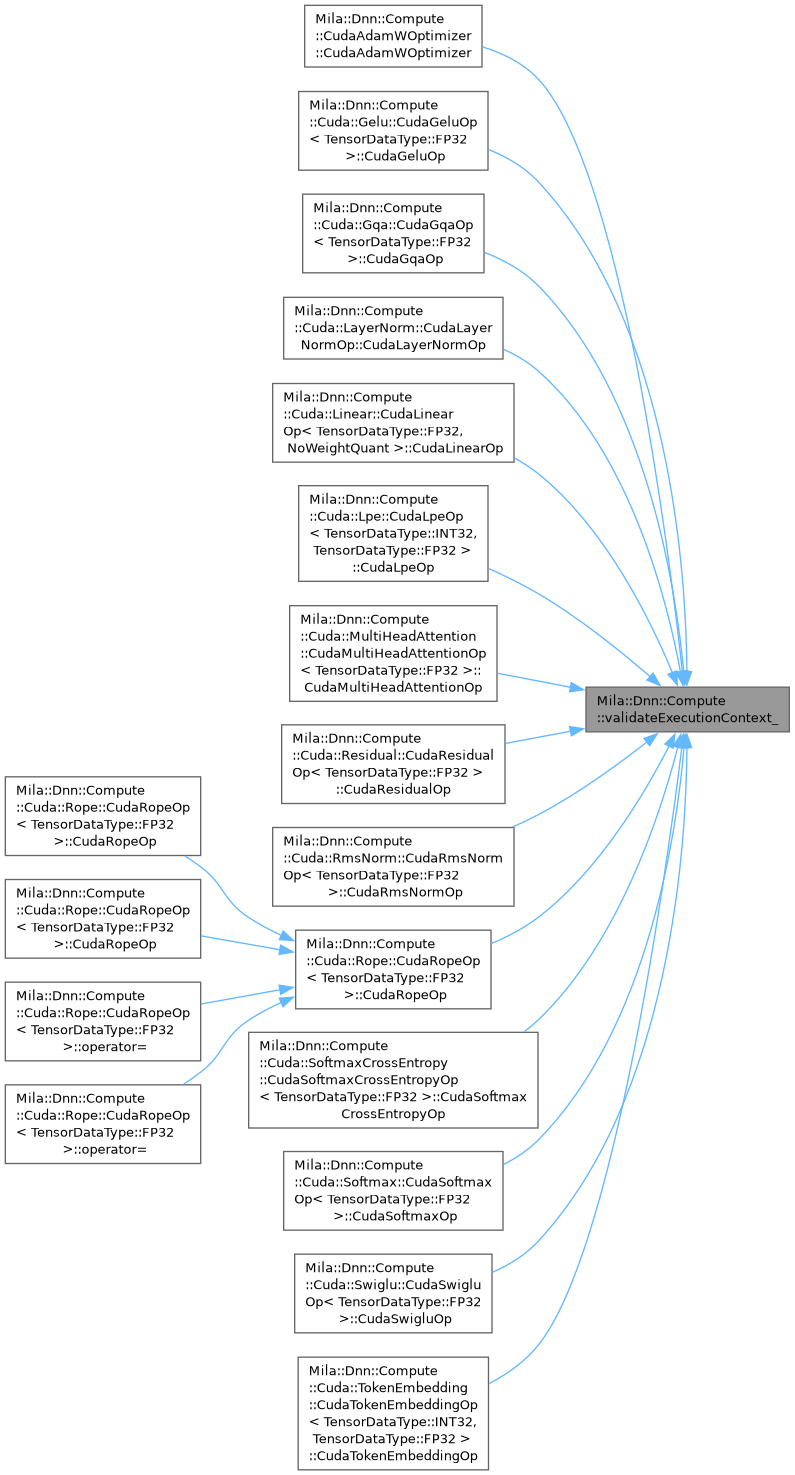
| template<DeviceType TDeviceType> |
| ExecutionContext< TDeviceType > * | Mila::Dnn::Compute::validateExecutionContext_ (IExecutionContext *context, const std::string &op_name) |