CUDA Grouped-Query Attention operation. More...

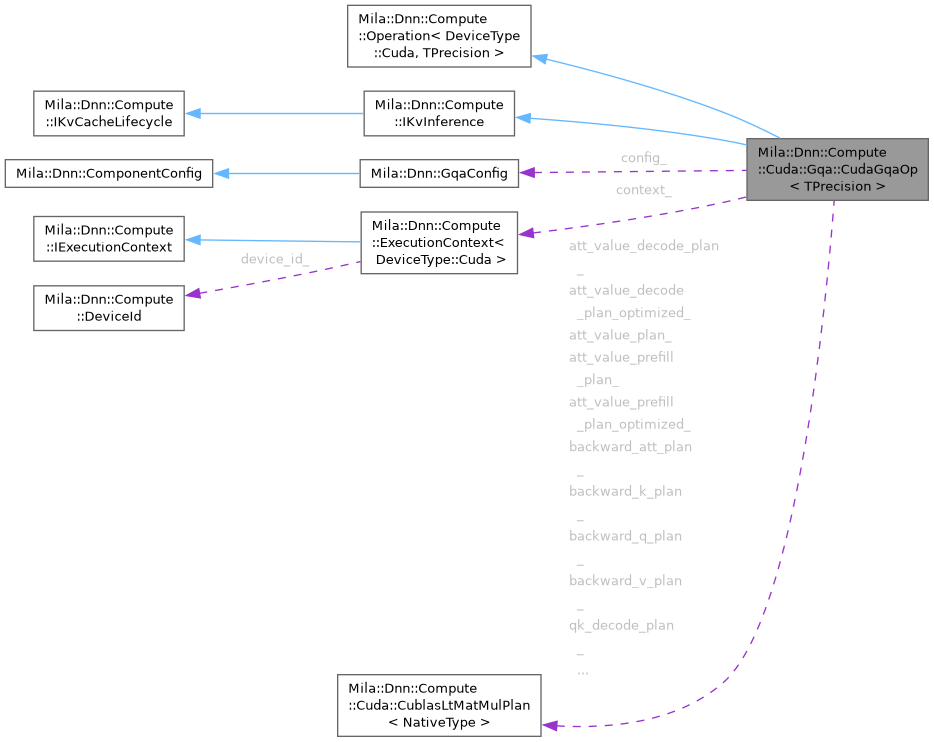
Public Types | |
| using | ConfigType = GqaConfig |
| using | CudaExecutionContext = ExecutionContext<DeviceType::Cuda> |
| using | MR = CudaDeviceMemoryResource |
| using | NativeType = typename Mila::Dnn::Compute::Cuda::TensorDataTypeMap<TPrecision>::device_type |
| using | TensorType = Tensor<TPrecision, MR> |
| using | UnaryOperationBase = UnaryOperation<DeviceType::Cuda, TPrecision> |
| Public Types inherited from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision > | |
| using | DataTypeTraits |
Public Member Functions | |
| CudaGqaOp (IExecutionContext *context, const GqaConfig &config) | |
| void | backward (const ITensor &input, const ITensor &output_grad, ITensor &input_grad) const |
| void | build (const BuildContext &context) override |
| Prepare the operation for a concrete input shape. | |
| void | decode (const ITensor &q, const ITensor &k, const ITensor &v, ITensor &output, int position) override |
| Process a single token at an explicit KV cache position. | |
| void | forward (const ITensor &input, ITensor &output) const |
| Standard (non-cached) forward pass used during training. | |
| const GqaConfig & | getConfig () const |
| std::string | getName () const override |
| Human-readable operation name. | |
| OperationType | getOperationType () const override |
| Operation type identifier. | |
| std::size_t | getStateMemorySize () const override |
| Returns the number of bytes of state memory allocated by this operation. | |
| void | initializeKvCache (int batch_size, int max_seq_length) override |
| Allocate the KV cache for a given batch size and maximum sequence length. | |
| void | prefill (const ITensor &q, const ITensor &k, const ITensor &v, ITensor &output, int position_offset) override |
| Populate the KV cache and compute attention output for a token chunk. | |
| void | resetKvCache () override |
| Reset the KV cache to an empty state, preserving the allocation. | |
| void | setGradients (ITensor *, ITensor *) override |
| Bind module-owned gradient tensors to the operation. | |
| void | setParameters (ITensor *, ITensor *) override |
| Bind module-owned parameter tensors to the operation. | |
| void | setState (const GqaState &state) |
| Wire the shared transient scratch buffers for the optimized inference path. | |
| Public Member Functions inherited from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision > | |
| virtual | ~Operation ()=default |
| virtual void | clearGradients () noexcept |
| Clear any cached gradient pointers held by the operation. | |
| virtual TensorDataType | getDataType () const |
| Tensor data type for this operation. | |
| virtual DeviceType | getDeviceType () const |
| Device type for this operation. | |
| virtual bool | isBuilt () const |
| Whether build() completed successfully for a concrete input shape. | |
| virtual bool | isEvalMode () const |
| Query whether operation is configured for training. | |
| virtual void | setTrainingMode (TrainingMode training_mode) |
| Configure operation training-mode behavior. | |
| Public Member Functions inherited from Mila::Dnn::Compute::IKvInference | |
| ~IKvInference () override=default | |
| Public Member Functions inherited from Mila::Dnn::Compute::IKvCacheLifecycle | |
| virtual | ~IKvCacheLifecycle ()=default |
Private Member Functions | |
| void | buildCublasLtPlans () |
| void | buildCublasLtPlans_optimized () |
| void | decode_optimized (const ITensor &q, const ITensor &k, const ITensor &v, ITensor &output, int position) |
| void | decodeImpl (const ITensor &q, const ITensor &k, const ITensor &v, ITensor &output, int position) |
| void | ensureKVCacheEnabled () const |
| void | getComputeTypes (cublasComputeType_t &compute_type, cudaDataType_t &scale_type) const |
| cudaDataType_t | getCudaDataType () const |
| const Detail::CublasLtMatMulPlan< NativeType > & | getOrBuildPartialAVPlan (int chunk_len) |
| const Detail::CublasLtMatMulPlan< NativeType > & | getOrBuildPartialAVPlan_optimized (int chunk_len) |
| const Detail::CublasLtMatMulPlan< NativeType > & | getOrBuildPartialQKPlan (int chunk_len) |
| const Detail::CublasLtMatMulPlan< NativeType > & | getOrBuildPartialQKPlan_optimized (int chunk_len) |
| void | initializeState (const BuildContext &build_context) |
| void | initializeState_optimized (const BuildContext &build_context) |
| void | prefill_optimized (const ITensor &q, const ITensor &k, const ITensor &v, ITensor &output, int position_offset) |
| void | prefillImpl (const ITensor &q, const ITensor &k, const ITensor &v, ITensor &output, int position_offset) |
| void | validateDecodeInputShape (const shape_t &s) const |
| void | validateInputShape (const shape_t &s) const |
| void | validatePrefillInputShape (const shape_t &s) const |
Static Private Member Functions | |
| static NativeType * | raw (const std::shared_ptr< TensorType > &t) |
Additional Inherited Members | |
| Static Public Attributes inherited from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision > | |
| static constexpr TensorDataType | data_type |
| static constexpr DeviceType | device_type |
| Protected Attributes inherited from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision > | |
| bool | is_built_ |
| TrainingMode | training_mode_ |
Detailed Description
requires PrecisionSupportedOnDevice<TPrecision, DeviceType::Cuda>
class Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >
CUDA Grouped-Query Attention operation.
GQA generalises MHA by allowing num_kv_heads < num_heads. Every group of (num_heads / num_kv_heads) Q heads shares a single K/V head, reducing KV cache memory and bandwidth proportionally to the group size.
The legacy path uses cuBLASLt batched matmuls on an expanded layout: K and V are stored compactly in [B, NKV, T, HS] and expanded to [B, NH, T, HS] before the matmuls so every cuBLASLt plan operates at batch_count = B * NH.
The optimized path (kUseOptimizedPath) eliminates the expansion buffers and q_tensor_ by rebuilding cuBLASLt plans against the compact NKV layout with grouped head strides. See GqaMemory.md Phase 1 and Phase 2.
Forward pass (training):
- permute_qkv -> Q[B,NH,T,HS], K[B,NKV,T,HS], V[B,NKV,T,HS]
- expand_kv -> k_exp/v_exp [B,NH,T,HS]
- qk_score_plan -> preatt [B,NH,T,T]
- softmax_forward -> att [B,NH,T,T]
- att_value_plan -> v_out [B,NH,T,HS]
- unpermute_output -> Y [B,T,NH*HS]
Prefill pass (inference only, with KV cache):
- prefill_permute_qkv -> Q[B,NH,chunk,HS], K/V[B,NKV,chunk,HS] (padded to T)
- prefill_expand_kv -> k_exp/v_exp [B,NH,chunk,HS] (padded to T)
- prefill_qk_plan -> preatt [B,NH,chunk,T]
- prefill_softmax -> att [B,NH,chunk,T]
- prefill_att_value_plan -> v_out [B,NH,chunk,HS]
- prefill_unpermute_output -> Y [B,chunk,C]
Decode pass (decode / KV-cache):
- permute_qkv_decode -> single Q token; append K/V to cache
- expand_kv -> expand cache slice up to current position
- qk_decode_plan -> preatt_decode [B,NH,1,T]
- softmax_decode -> att_decode
- att_value_decode -> v_out_decode [B,NH,1,HS]
- unpermute_output -> Y [B,1,C]
Backward pass (training only):
- unpermute_backward -> dVout [B,NH,T,HS]
- backward_v_plan -> dV_exp (expanded)
- backward_att_plan -> dAtt
- softmax_backward -> dPreatt
- backward_q_plan -> dQ
- backward_k_plan -> dK_exp (expanded)
- reduce_kv_grad -> dK/dV [B,NKV,T,HS] (sum over group)
- permute_backward -> dX [B,T,(NH+2*NKV)*HS]
- Template Parameters
-
TPrecision Tensor element type and cuBLASLt data/compute type.
Member Typedef Documentation
◆ ConfigType
| using Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >::ConfigType = GqaConfig |
◆ CudaExecutionContext
| using Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >::CudaExecutionContext = ExecutionContext<DeviceType::Cuda> |
◆ MR
| using Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >::MR = CudaDeviceMemoryResource |
◆ NativeType
| using Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >::NativeType = typename Mila::Dnn::Compute::Cuda::TensorDataTypeMap<TPrecision>::device_type |
◆ TensorType
| using Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >::TensorType = Tensor<TPrecision, MR> |
◆ UnaryOperationBase
| using Mila::Dnn::Compute::Cuda::Gqa::CudaGqaOp< TPrecision >::UnaryOperationBase = UnaryOperation<DeviceType::Cuda, TPrecision> |
Constructor & Destructor Documentation
◆ CudaGqaOp()
|
inline |
Member Function Documentation
◆ backward()
|
inline |
◆ build()
|
inlineoverridevirtual |
Prepare the operation for a concrete input shape.
Default implementation is a no-op. Operations requiring shape-dependent setup should override this method.
Reimplemented from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision >.
◆ buildCublasLtPlans()
|
inlineprivate |
◆ buildCublasLtPlans_optimized()
|
inlineprivate |

◆ decode()
|
inlineoverridevirtual |
Process a single token at an explicit KV cache position.
- Parameters
-
q Query [B, 1, n_heads * head_dim]. k Key [B, 1, n_kv_heads * head_dim]. v Value [B, 1, n_kv_heads * head_dim]. output Pre-allocated output [B, 1, model_dim]. position Zero-based absolute sequence position into the KV cache.
Implements Mila::Dnn::Compute::IKvInference.
◆ decode_optimized()
|
inlineprivate |
◆ decodeImpl()
|
inlineprivate |
◆ ensureKVCacheEnabled()
|
inlineprivate |
◆ forward()
|
inline |
Standard (non-cached) forward pass used during training.
◆ getComputeTypes()
|
inlineprivate |
◆ getConfig()
|
inline |
◆ getCudaDataType()
|
inlineprivate |
◆ getName()
|
inlineoverridevirtual |
Human-readable operation name.
Implements Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision >.
◆ getOperationType()
|
inlineoverridevirtual |
Operation type identifier.
Implements Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision >.
◆ getOrBuildPartialAVPlan()
|
inlineprivate |
◆ getOrBuildPartialAVPlan_optimized()
|
inlineprivate |
◆ getOrBuildPartialQKPlan()
|
inlineprivate |
◆ getOrBuildPartialQKPlan_optimized()
|
inlineprivate |
◆ getStateMemorySize()
|
inlineoverridevirtual |
Returns the number of bytes of state memory allocated by this operation.
State memory includes build-time buffers such as caches and scratch allocations. Parameters and gradients are owned at the component level and are not included.
Override in derived operations that allocate device or host state during build().
Reimplemented from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision >.
◆ initializeKvCache()
|
inlineoverridevirtual |
Allocate the KV cache for a given batch size and maximum sequence length.
- Parameters
-
batch_size Number of sequences in the batch. max_sequence_length Maximum number of tokens the cache must hold.
Implements Mila::Dnn::Compute::IKvCacheLifecycle.
◆ initializeState()
|
inlineprivate |
◆ initializeState_optimized()
|
inlineprivate |
◆ prefill()
|
inlineoverridevirtual |
Populate the KV cache and compute attention output for a token chunk.
- Parameters
-
q Query [B, T_chunk, n_heads * head_dim]. k Key [B, T_chunk, n_kv_heads * head_dim]. v Value [B, T_chunk, n_kv_heads * head_dim]. output Pre-allocated output [B, T_chunk, model_dim]. position_offset Absolute position of the first token in this chunk.
Implements Mila::Dnn::Compute::IKvInference.
◆ prefill_optimized()
|
inlineprivate |
◆ prefillImpl()
|
inlineprivate |
◆ raw()
|
inlinestaticprivate |
◆ resetKvCache()
|
inlineoverridevirtual |
Reset the KV cache to an empty state, preserving the allocation.
Implements Mila::Dnn::Compute::IKvCacheLifecycle.
◆ setGradients()
|
inlineoverridevirtual |
Bind module-owned gradient tensors to the operation.
New canonical API for binding gradient buffers. Mirrors semantics of setParameters() but for gradients used during backward().
The operation MUST NOT take ownership of the provided pointers. Implementations may cache rawData() pointers for hot-path writes.
Default: no-op for stateless operations.
Reimplemented from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision >.
◆ setParameters()
|
inlineoverridevirtual |
Bind module-owned parameter tensors to the operation.
The module retains ownership of the provided ITensor objects. Implementations may cache rawData() pointers for hot-path access but MUST NOT free the provided pointers.
Default: no-op for stateless operations.
Reimplemented from Mila::Dnn::Compute::Operation< DeviceType::Cuda, TPrecision >.
◆ setState()
|
inline |
Wire the shared transient scratch buffers for the optimized inference path.
Called once per build by LlamaTransformer after all blocks are built. The tensors are owned by LlamaTransformer and shared across all GQA layers sequentially. Must be called before prefill() or decode() when use_optimized_path_ is true.
- Parameters
-
state Non-owning pointers to the shared workspace tensors. All slots must be non-null for the optimized inference path.
◆ validateDecodeInputShape()
|
inlineprivate |
◆ validateInputShape()
|
inlineprivate |
◆ validatePrefillInputShape()
|
inlineprivate |
Member Data Documentation
◆ active_max_seq_len_
|
private |
◆ att_
|
private |
◆ att_decode_
|
private |
◆ att_decode_opt_
|
private |
◆ att_decode_tensor_
|
private |
◆ att_opt_
|
private |
◆ att_tensor_
|
private |
◆ att_tensor_optimized_
|
private |
◆ att_value_decode_plan_
|
private |
◆ att_value_decode_plan_optimized_
|
private |
◆ att_value_partial_prefill_plan_cache_
|
private |
◆ att_value_partial_prefill_plan_cache_optimized_
|
private |
◆ att_value_plan_
|
private |
◆ att_value_prefill_plan_
|
private |
◆ att_value_prefill_plan_optimized_
|
private |
◆ B_
|
private |
Batch size.
◆ backward_att_plan_
|
private |
◆ backward_k_plan_
|
private |
◆ backward_q_plan_
|
private |
◆ backward_v_plan_
|
private |
◆ C_
|
private |
Model dim = NH * HS.
◆ cached_seq_len_
|
private |
◆ config_
|
private |
◆ context_
|
private |
◆ cublaslt_handle_
|
private |
◆ datt_
|
private |
◆ datt_tensor_
|
private |
◆ dK_
|
private |
◆ dK_exp_
|
private |
◆ dK_exp_tensor_
|
private |
◆ dK_tensor_
|
private |
◆ dpreatt_
|
private |
◆ dpreatt_tensor_
|
private |
◆ dq_
|
private |
◆ dq_tensor_
|
private |
◆ dV_
|
private |
◆ dV_exp_
|
private |
◆ dV_exp_tensor_
|
private |
◆ dV_tensor_
|
private |
◆ dVout_
|
private |
◆ dVout_tensor_
|
private |
◆ GS_
|
private |
Group size = NH / NKV.
◆ HS_
|
private |
Head dim = C / NH.
◆ k_
|
private |
◆ k_exp_
|
private |
◆ k_exp_tensor_
|
private |
◆ k_opt_
|
private |
◆ k_tensor_
|
private |
◆ kv_cache_enabled_
|
private |
◆ NH_
|
private |
Number of Q heads.
◆ NKV_
|
private |
Number of KV heads.
◆ preatt_
|
private |
◆ preatt_decode_
|
private |
◆ preatt_decode_opt_
|
private |
◆ preatt_decode_tensor_
|
private |
◆ preatt_opt_
|
private |
◆ preatt_tensor_
|
private |
◆ preatt_tensor_optimized_
|
private |
◆ prefill_chunk_size_
|
private |
◆ q_
|
private |
◆ q_permute_opt_
|
private |
◆ q_permute_tensor_optimized_
|
private |
◆ q_tensor_
|
private |
◆ qk_decode_plan_
|
private |
◆ qk_decode_plan_optimized_
|
private |
◆ qk_partial_prefill_plan_cache_
|
private |
◆ qk_partial_prefill_plan_cache_optimized_
|
private |
◆ qk_prefill_plan_
|
private |
◆ qk_prefill_plan_optimized_
|
private |
◆ qk_score_plan_
|
private |
◆ state_memory_size_
|
private |
◆ T_
|
private |
Max sequence length.
◆ use_optimized_path_
|
private |
◆ v_
|
private |
◆ v_exp_
|
private |
◆ v_exp_tensor_
|
private |
◆ v_opt_
|
private |
◆ v_out_
|
private |
◆ v_out_decode_
|
private |
◆ v_out_decode_opt_
|
private |
◆ v_out_decode_tensor_
|
private |
◆ v_out_opt_
|
private |
◆ v_out_tensor_
|
private |
◆ v_out_tensor_optimized_
|
private |
◆ v_tensor_
|
private |
The documentation for this class was generated from the following file:
- /__w/Mila/Mila/Mila/Src/Dnn/Compute/Devices/Cuda/Operations/Attention/GQA/CudaGqaOp.ixx