CUDA implementation of the Rope (rotary positional embedding) operation. More...

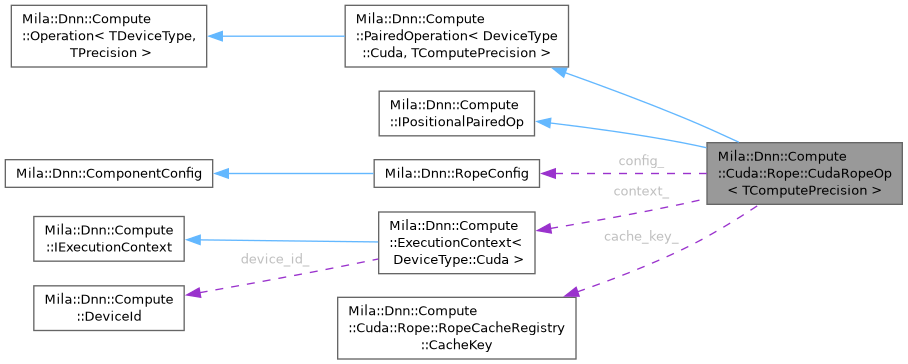
Public Types | |
| using | CacheKey = RopeCacheRegistry::CacheKey |
| using | ComputeType = typename Mila::Dnn::Compute::Cuda::TensorDataTypeMap<TComputePrecision>::device_type |
| using | ConfigType = RopeConfig |
| using | CudaExecutionContext = ExecutionContext<DeviceType::Cuda> |
| using | MR = CudaDeviceMemoryResource |
| using | TensorType = Tensor<TComputePrecision, MR> |
| Public Types inherited from Mila::Dnn::Compute::PairedOperation< DeviceType::Cuda, TComputePrecision > | |
| using | MR |
| using | TensorInputAType |
| using | TensorInputBType |
| using | TensorOutputType |
| Public Types inherited from Mila::Dnn::Compute::Operation< TDeviceType, TPrecision > | |
| using | DataTypeTraits |
Public Member Functions | |
| CudaRopeOp (const CudaRopeOp &)=delete | |
| CudaRopeOp (CudaRopeOp &&other) noexcept | |
| CudaRopeOp (IExecutionContext *context, const RopeConfig &config) | |
| ~CudaRopeOp () | |
| void | backward (const ITensor &dQ_out, const ITensor &dK_out, ITensor &dQ_in, ITensor &dK_in) const override |
| Backward pass (hot path). | |
| void | build (const BuildContext &build_context) override |
| Prepare the operation for a concrete input shape (cold path). | |
| void | decode (const ITensor &Q_in, const ITensor &K_in, ITensor &Q_out, ITensor &K_out, int position) override |
| Single-token decode with explicit position. | |
| void | forward (const ITensor &Q_in, const ITensor &K_in, ITensor &Q_out, ITensor &K_out) const override |
| Full-sequence forward pass. | |
| std::string | getName () const override |
| Human-readable operation name. | |
| OperationType | getOperationType () const override |
| Operation type identifier. | |
| std::size_t | getStateMemorySize () const override |
| Returns the number of bytes of state memory allocated by this operation. | |
| CudaRopeOp & | operator= (const CudaRopeOp &)=delete |
| CudaRopeOp & | operator= (CudaRopeOp &&other) noexcept |
| void | prefill (const ITensor &Q_in, const ITensor &K_in, ITensor &Q_out, ITensor &K_out, int position_offset) override |
| Chunked prefill with explicit position offset. | |
| Public Member Functions inherited from Mila::Dnn::Compute::PairedOperation< DeviceType::Cuda, TComputePrecision > | |
| virtual | ~PairedOperation ()=default |
| Public Member Functions inherited from Mila::Dnn::Compute::Operation< TDeviceType, TPrecision > | |
| virtual | ~Operation ()=default |
| virtual void | clearGradients () noexcept |
| Clear any cached gradient pointers held by the operation. | |
| virtual TensorDataType | getDataType () const |
| Tensor data type for this operation. | |
| virtual DeviceType | getDeviceType () const |
| Device type for this operation. | |
| virtual bool | isBuilt () const |
| Whether build() completed successfully for a concrete input shape. | |
| virtual bool | isEvalMode () const |
| Query whether operation is configured for training. | |
| virtual void | setGradients (ITensor *weight_grad, ITensor *bias_grad) |
| Bind module-owned gradient tensors to the operation. | |
| virtual void | setParameters (ITensor *weight, ITensor *bias) |
| Bind module-owned parameter tensors to the operation. | |
| virtual void | setTrainingMode (TrainingMode training_mode) |
| Configure operation training-mode behavior. | |
| Public Member Functions inherited from Mila::Dnn::Compute::IPositionalPairedOp | |
| virtual | ~IPositionalPairedOp ()=default |
Private Member Functions | |
| void | dispatchForward (const ITensor &Q_in, const ITensor &K_in, ITensor &Q_out, ITensor &K_out, int B, int T, int position_offset) const |
| void | ensureBuilt () const |
| CacheKey | makeCacheKey () const noexcept |
| void | releaseCache () noexcept |
| void | validateRuntimeShape (int B, int T) const |
Private Attributes | |
| int | batch_size_ { 0 } |
| CacheKey | cache_key_ {} |
| RopeConfig | config_ |
| CudaExecutionContext * | context_ |
| float * | cos_cache_ { nullptr } |
| bool | owns_cache_ { false } |
| int | seq_length_ { 0 } |
| float * | sin_cache_ { nullptr } |
Additional Inherited Members | |
| Static Public Attributes inherited from Mila::Dnn::Compute::Operation< TDeviceType, TPrecision > | |
| static constexpr TensorDataType | data_type |
| static constexpr DeviceType | device_type |
| Static Protected Member Functions inherited from Mila::Dnn::Compute::PairedOperation< DeviceType::Cuda, TComputePrecision > | |
| static const TensorInputAType & | asInputA (const ITensor &t) |
| static const TensorInputBType & | asInputB (const ITensor &t) |
| static TensorOutputType & | asOutputTensor (ITensor &t) |
| Protected Attributes inherited from Mila::Dnn::Compute::Operation< TDeviceType, TPrecision > | |
| bool | is_built_ |
| TrainingMode | training_mode_ |
Detailed Description
requires PrecisionSupportedOnDevice<TComputePrecision, DeviceType::Cuda>
class Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >
CUDA implementation of the Rope (rotary positional embedding) operation.
Takes the projected Q and K tensors produced by linear layers and applies position-dependent rotations so that attention scores encode relative position implicitly through the inner product.
Design:
- No learned parameters. The cos/sin cache is computed from fixed frequencies on the first build() call and shared across all ops with identical parameters via RopeCacheRegistry. Subsequent ops with the same config reuse the existing device allocation; build_cache() is called exactly once per unique config.
- Two-phase initialization: build() acquires the shared cache and validates shapes; forward(), backward(), prefill(), and decode() are pure hot-path dispatch.
- GQA-aware: Q and K may have different head counts (n_heads vs n_kv_heads).
- Backward is exact: RoPE is an orthogonal rotation, so the gradient is the inverse rotation (negate sin terms). No extra buffers needed.
Input/output shapes: Q: [B, T, n_heads, head_dim] K: [B, T, n_kv_heads, head_dim] Q', K' – same shapes as inputs.
Decode shapes (T=1, explicit position): Q: [B, 1, n_heads, head_dim] K: [B, 1, n_kv_heads, head_dim]
- Template Parameters
-
TPrecision Precision of Q/K tensors (FP32 or FP16).
Member Typedef Documentation
◆ CacheKey
| using Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >::CacheKey = RopeCacheRegistry::CacheKey |
◆ ComputeType
| using Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >::ComputeType = typename Mila::Dnn::Compute::Cuda::TensorDataTypeMap<TComputePrecision>::device_type |
◆ ConfigType
| using Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >::ConfigType = RopeConfig |
◆ CudaExecutionContext
| using Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >::CudaExecutionContext = ExecutionContext<DeviceType::Cuda> |
◆ MR
| using Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >::MR = CudaDeviceMemoryResource |
◆ TensorType
| using Mila::Dnn::Compute::Cuda::Rope::CudaRopeOp< TComputePrecision >::TensorType = Tensor<TComputePrecision, MR> |
Constructor & Destructor Documentation
◆ CudaRopeOp() [1/3]
|
inline |
◆ ~CudaRopeOp()
|
inline |
◆ CudaRopeOp() [2/3]
|
delete |
◆ CudaRopeOp() [3/3]
|
inlinenoexcept |
Member Function Documentation
◆ backward()
|
inlineoverridevirtual |
Backward pass (hot path).
RoPE is an orthogonal rotation (R^T R = I), so the Jacobian is R^T. The backward pass is therefore the inverse rotation: rotate the upstream gradients by -theta (negate sin terms). No new parameters are accumulated.
Implements Mila::Dnn::Compute::PairedOperation< DeviceType::Cuda, TComputePrecision >.
◆ build()
|
inlineoverridevirtual |
Prepare the operation for a concrete input shape (cold path).
On the first call, acquires a shared cos/sin cache from RopeCacheRegistry and fills it if this is the first op with this configuration. Subsequent calls on the same instance update the runtime shape limits only; the shared cache is not re-acquired.
- Parameters
-
build_context Build context carrying the Q/K input shape [B, T, ...].
Reimplemented from Mila::Dnn::Compute::Operation< TDeviceType, TPrecision >.
◆ decode()
|
inlineoverridevirtual |
Single-token decode with explicit position.
Reads only the cache row at position. Used for KV-cache autoregressive generation where T=1.
- Parameters
-
Q_in Input Q [B, 1, n_heads, head_dim]. K_in Input K [B, 1, n_kv_heads, head_dim]. Q_out Output Q [B, 1, n_heads, head_dim]. K_out Output K [B, 1, n_kv_heads, head_dim]. position Zero-based absolute sequence position.
Implements Mila::Dnn::Compute::IPositionalPairedOp.
◆ dispatchForward()
|
inlineprivate |
◆ ensureBuilt()
|
inlineprivate |
◆ forward()
|
inlineoverridevirtual |
Full-sequence forward pass.
Applies RoPE to Q and K across the full sequence with position_offset = 0. Used for training forward passes.
Implements Mila::Dnn::Compute::PairedOperation< DeviceType::Cuda, TComputePrecision >.
◆ getName()
|
inlineoverridevirtual |
Human-readable operation name.
Implements Mila::Dnn::Compute::Operation< TDeviceType, TPrecision >.
◆ getOperationType()
|
inlineoverridevirtual |
Operation type identifier.
Implements Mila::Dnn::Compute::Operation< TDeviceType, TPrecision >.
◆ getStateMemorySize()
|
inlineoverridevirtual |
Returns the number of bytes of state memory allocated by this operation.
State memory includes build-time buffers such as caches and scratch allocations. Parameters and gradients are owned at the component level and are not included.
Override in derived operations that allocate device or host state during build().
Reimplemented from Mila::Dnn::Compute::Operation< TDeviceType, TPrecision >.
◆ makeCacheKey()
|
inlineprivatenoexcept |

◆ operator=() [1/2]
|
delete |
◆ operator=() [2/2]
|
inlinenoexcept |
◆ prefill()
|
inlineoverridevirtual |
Chunked prefill with explicit position offset.
Applies RoPE to Q and K using absolute positions [position_offset .. position_offset + T - 1] for the cos/sin cache lookup.
- Parameters
-
Q_in Input Q [B, T, n_heads, head_dim]. K_in Input K [B, T, n_kv_heads, head_dim]. Q_out Output Q [B, T, n_heads, head_dim]. K_out Output K [B, T, n_kv_heads, head_dim]. position_offset Absolute position of the first token in this chunk.
Implements Mila::Dnn::Compute::IPositionalPairedOp.
◆ releaseCache()
|
inlineprivatenoexcept |
◆ validateRuntimeShape()
|
inlineprivate |
Member Data Documentation
◆ batch_size_
|
private |
◆ cache_key_
|
private |
◆ config_
|
private |
◆ context_
|
private |
◆ cos_cache_
|
private |
◆ owns_cache_
|
private |
◆ seq_length_
|
private |
◆ sin_cache_
|
private |
The documentation for this class was generated from the following file:
- /__w/Mila/Mila/Mila/Src/Dnn/Compute/Devices/Cuda/Operations/Encodings/Rope/CudaRopeOp.ixx