Transformer encoder block as a composite component. More...
Public Types | |
| using | AttentionType = MultiHeadAttention<TDeviceType, TPrecision> |
| using | ComponentPtr = typename CompositeComponentBase::ComponentPtr |
| using | CompositeComponentBase = CompositeComponent<TDeviceType, TPrecision> |
| using | ExecutionContextType = ExecutionContext<TDeviceType> |
| using | LayerNormType = LayerNorm<TDeviceType, TPrecision> |
| using | LinearType = Linear<TDeviceType, TPrecision> |
| using | MLPType = MLP<TDeviceType, TPrecision> |
| using | MR = typename DeviceTypeTraits<TDeviceType>::memory_resource |
| using | ResidualType = Residual<TDeviceType, TPrecision> |
| using | TensorType = Tensor<TPrecision, MR> |
| Public Types inherited from Mila::Dnn::CompositeComponent< TDeviceType, TPrecision > | |
| using | ComponentBase = Component<TDeviceType, TPrecision> |
| using | ComponentPtr = std::shared_ptr<Component<TDeviceType, TPrecision>> |
Public Member Functions | |
| GptBlock (const std::string &name, const GptBlockConfig &config, std::optional< DeviceId > device_id=std::nullopt) | |
| Construct GptBlock in shared or standalone mode. | |
| ~GptBlock () override=default | |
| TensorType & | backward (const TensorType &input, const TensorType &output_grad) |
| Backward pass returning the input-gradient tensor. | |
| TensorType & | decode (const TensorType &input, int position) |
| Inference-only single-token decode pass. | |
| TensorType & | forward (const TensorType &input) |
| Forward pass with optional KV cache dispatch. | |
| MemoryStats | getMemoryStats () const override |
| Return the current memory allocation breakdown for this component. | |
| const ComponentType | getType () const override |
| Get the component type identifier. | |
| void | initializeKVCache (int64_t max_seq_len) |
| Allocate KV cache buffers on the contained Attention component. | |
| void | load_ (ModelArchive &archive, SerializationMode mode) |
| void | resetKVCache () |
| Reset KV cache state on the contained Attention component. | |
| void | save_ (ModelArchive &archive, SerializationMode mode) const override |
| Save all child components recursively. | |
| bool | supportsKVCache () const noexcept |
| Returns true when the contained Attention supports KV caching. | |
| std::string | toString () const override |
| Generate a human-readable description. | |
| void | zeroGradients () override |
| Clear all model-owned gradients for this component. | |
| Public Member Functions inherited from Mila::Dnn::CompositeComponent< TDeviceType, TPrecision > | |
| CompositeComponent (CompositeComponent &&) noexcept=default | |
| CompositeComponent (const CompositeComponent &)=delete | |
| CompositeComponent (const std::string &name) | |
| Construct composite component with name. | |
| virtual | ~CompositeComponent ()=default |
| CompositeComponent & | addComponent (ComponentPtr component) |
| Add a pre-constructed child component (chainable). | |
| size_t | childCount () const noexcept |
| Get the number of direct children. | |
| void | clearComponents () |
| Clear all child components. | |
| ComponentPtr | findComponent (const std::string &path) const |
| Resolve a dot-separated component path within this composite. | |
| ComponentPtr | getComponent (const std::string &name) const |
| Retrieve a direct child component by name. | |
| const std::vector< ComponentPtr > & | getComponents () const |
| Get all child components in insertion order. | |
| DeviceId | getDeviceId () const override |
| Get the compute device for this composite. | |
| std::vector< ITensor * > | getGradients () const override |
| Get all parameter gradients from all children. | |
| std::vector< ITensor * > | getParameters () const override |
| Get all parameters from all children. | |
| bool | hasChildren () const noexcept |
| Check if this composite has any children. | |
| bool | hasComponent (const std::string &name) const |
| Check if a named child component exists. | |
| CompositeComponent & | operator= (CompositeComponent &&) noexcept=default |
| CompositeComponent & | operator= (const CompositeComponent &)=delete |
| size_t | parameterCount () const override |
| Count parameters across all children. | |
| bool | removeComponent (const std::string &name) |
| Get the named child components map. | |
| void | synchronize () override |
| Synchronize all child components. | |
| ComponentPtr | tryFindComponent (const std::string &path) const |
| Try to resolve a dot-separated component path within this composite. | |
| Public Member Functions inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| Component (const std::string &name) | |
| Construct component with required name identifier. | |
| virtual | ~Component ()=default |
| virtual void | build (const BuildContext &context) final |
| Build the component with the provided BuildContext (canonical overload). | |
| const std::string | getName () const |
| Get the component's name identifier. | |
| virtual std::vector< std::string > | getParameterNames () const |
| List all available parameter names for this component. | |
| RuntimeMode | getRuntimeMode () const noexcept |
| Convenience accessor — true if currently in Eval mode. | |
| TrainingMode | getTrainingMode () const noexcept |
| The current runtime behavioral mode of this Component. | |
| virtual bool | isBuilt () const final |
| Returns true if build() has completed successfully. | |
| bool | isInferenceMode () const noexcept |
| bool | isTrainingMode () const noexcept |
| virtual void | loadParameter (const std::string &name, const Serialization::ITensorBlob &blob) |
| Load a parameter from serialized tensor data. | |
| void | setTrainingMode (TrainingMode mode) |
| Set the runtime behavioral mode for this Component. | |
Protected Member Functions | |
| void | onBuilding (const BuildContext &context) override |
| Hook invoked by build() to allocate component buffers. | |
| void | onTrainingModeChanging (TrainingMode training_mode) override |
| Hook invoked when training mode is about to change. | |
| Protected Member Functions inherited from Mila::Dnn::CompositeComponent< TDeviceType, TPrecision > | |
| template<typename TComponent> | |
| std::shared_ptr< TComponent > | getComponentAs (const std::string &name) const |
| Retrieve a typed child component by name. | |
| void | onExecutionContextSet () override |
| Hook invoked after ExecutionContext is set. | |
| virtual void | optimize () |
| Virtual hook for graph optimization after construction. | |
| Protected Member Functions inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| IExecutionContext * | getExecutionContext () const |
| Get the shared execution context. | |
| bool | hasExecutionContext () const noexcept |
| Check if execution context has been set. | |
| template<TensorDataType TParameterPrecision, typename TMemoryResource> | |
| void | loadParameterFromBlob (const std::string ¶m_name, const Serialization::ITensorBlob &blob, Tensor< TParameterPrecision, TMemoryResource > &target, const shape_t &expected_shape) |
| Load a tensor blob into a parameter tensor with validation. | |
| void | setExecutionContext (IExecutionContext *context) |
| Set the execution context for this component. | |
Private Member Functions | |
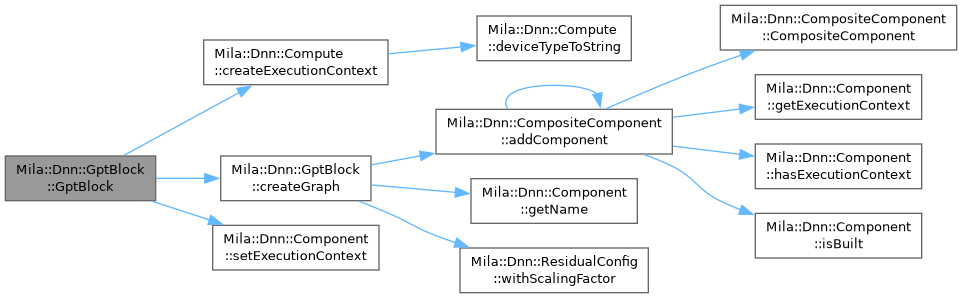
| void | createGraph () |
| void | validateBuildContext (const BuildContext &context) const |
| void | validateInputShape (const shape_t &input_shape) const |
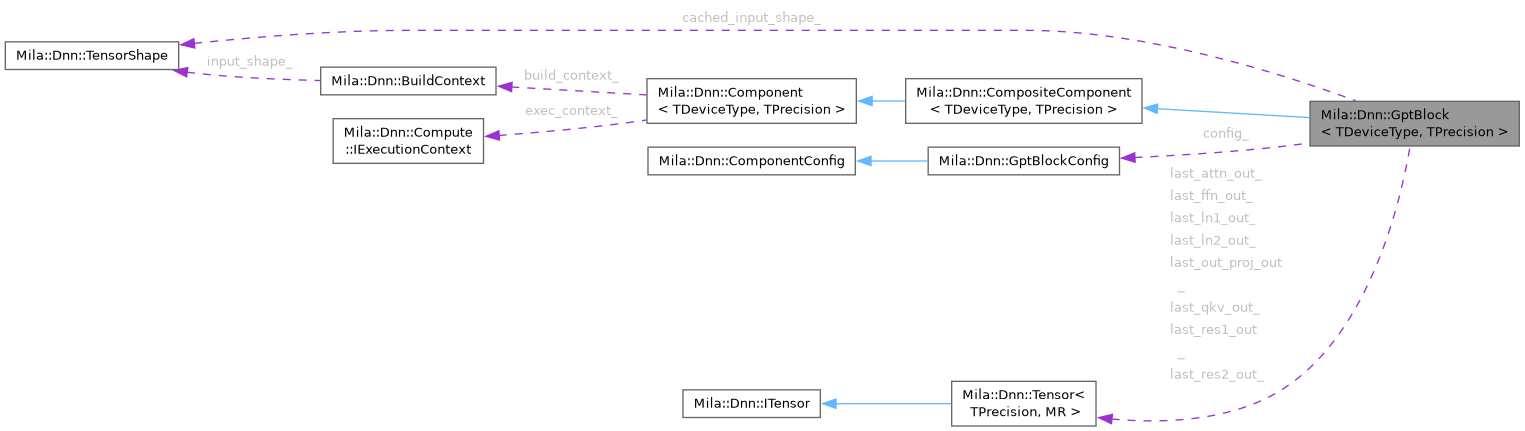
Private Attributes | |
| std::shared_ptr< AttentionType > | attn_ { nullptr } |
| shape_t | cached_input_shape_ |
| GptBlockConfig | config_ |
| std::shared_ptr< TensorType > | d_input_ { nullptr } |
| std::shared_ptr< TensorType > | d_res1_accum_ { nullptr } |
| std::shared_ptr< MLPType > | ffn_ { nullptr } |
| bool | forward_executed_ { false } |
| TensorType * | last_attn_out_ { nullptr } |
| TensorType * | last_ffn_out_ { nullptr } |
| TensorType * | last_ln1_out_ { nullptr } |
| TensorType * | last_ln2_out_ { nullptr } |
| TensorType * | last_out_proj_out_ { nullptr } |
| TensorType * | last_qkv_out_ { nullptr } |
| TensorType * | last_res1_out_ { nullptr } |
| TensorType * | last_res2_out_ { nullptr } |
| std::shared_ptr< LayerNormType > | ln1_ { nullptr } |
| std::shared_ptr< LayerNormType > | ln2_ { nullptr } |
| std::shared_ptr< LinearType > | out_proj_ { nullptr } |
| std::unique_ptr< IExecutionContext > | owned_exec_context_ { nullptr } |
| std::shared_ptr< LinearType > | qkv_proj_ { nullptr } |
| std::shared_ptr< ResidualType > | res1_ { nullptr } |
| std::shared_ptr< ResidualType > | res2_ { nullptr } |
Additional Inherited Members | |
| Static Public Member Functions inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| static constexpr DeviceType | getDeviceType () |
| Compile-time device type for this component instance. | |
| static constexpr TensorDataType | getPrecision () noexcept |
| Compile-time tensor precision for this component instance. | |
| Protected Attributes inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| BuildContext | build_context_ { shape_t{ 1 }, RuntimeMode::Training } |
| The BuildContext stored at build time. | |
Detailed Description
requires PrecisionSupportedOnDevice<TPrecision, TDeviceType>
class Mila::Dnn::GptBlock< TDeviceType, TPrecision >
Transformer encoder block as a composite component.
Device-templated composite component that composes: LayerNorm -> QKV projection -> MultiHeadSelfAttention -> Residual -> LayerNorm -> MLP -> Residual
Construction follows the same patterns used by the MLP block:
- Graph created in constructor (context-independent)
- Optional owned ExecutionContext when a DeviceId is provided
- Shape-dependent build occurs in onBuilding()
KV cache support is surfaced via supportsKVCache() and managed via initializeKVCache() / resetKVCache(), which delegate to the contained Attention component. The KV cache dispatch itself is entirely driven by the AttentionForwardContext passed to forward() - GptBlock has no separate forwardPrefill / forwardDecode methods.
The AttentionForwardContext partition is imported but not re-exported. Only GptBlock and GptTransformer (and future transformer implementations) need visibility into it.
Constructor & Destructor Documentation
◆ GptBlock()
|
inlineexplicitexport |
Construct GptBlock in shared or standalone mode.
- Parameters
-
name Component name (used as prefix for sub-components). config Validated configuration for the block. device_id Optional DeviceId. When provided and matching TDeviceType, an owned ExecutionContext is created (standalone mode). Otherwise a parent is expected to set the context (shared mode).
◆ ~GptBlock()
|
overrideexportdefault |
Member Function Documentation
◆ backward()
|
inlineexport |
Backward pass returning the input-gradient tensor.
- Parameters
-
input Forward input previously passed to forward(). output_grad Gradient w.r.t. this block's output.
- Returns
- Reference to the owned input-gradient tensor.
◆ createGraph()
|
inlineexportprivate |

◆ decode()
|
inlineexport |
Inference-only single-token decode pass.
Runs all components with their standard forward() except Attention, which is called via decode(). Attention internally selects the fast KV cache path when available, or falls back to forward().
GptBlock is entirely unaware of which path Attention takes — the decode/fallback decision is Attention's private concern.
Precondition: forward() must have been called at least once on this block (via GptTransformer::forward or GptModel prefill pass) to populate the KV cache before decode() is called.
- Parameters
-
input Single-token input [B, 1, embedding_dim]. position Current sequence position (0-based).
- Returns
- Reference to block output tensor.
◆ forward()
|
inlineexport |
Forward pass with optional KV cache dispatch.
The default context (Mode::Standard) is the training and CPU inference path. During generate(), GptTransformer supplies a context with Mode::Prefill or Mode::Decode which is forwarded transparently to the contained Attention component. GptBlock itself has no awareness of prefill vs. decode semantics beyond passing the context through.
- Parameters
-
input Forward input tensor of shape [B, T, embedding_dim]. ctx Attention forward context. Defaults to Mode::Standard.
- Returns
- Reference to the block output tensor.
◆ getMemoryStats()
|
inlineoverrideexportvirtual |
Return the current memory allocation breakdown for this component.
Reflects allocations at the moment of the call. The returned stats naturally track the component lifecycle:
After construction — parameters only After build( Inference ) — parameters + T=1 state buffers After build( Training ) — parameters + T=full state buffers After setEvaluation( false ) — parameters + state + gradients
For CompositeComponent and Network, the returned stats are the recursive aggregate of all child components.
May be called at any time — no lifecycle preconditions.
- Returns
- MemoryStats reflecting current allocations.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.

◆ getType()
|
inlineoverrideexportvirtual |
Get the component type identifier.
Used for serialization and runtime type identification.
- Returns
- Component type enum value.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ initializeKVCache()
|
inlineexport |
Allocate KV cache buffers on the contained Attention component.
Intended to be called exclusively by the owning transformer's generate() during session setup.
- Parameters
-
max_seq_len Maximum sequence length the cache must accommodate.

◆ load_()
|
inlineexport |
◆ onBuilding()
|
inlineoverrideexportprotectedvirtual |
Hook invoked by build() to allocate component buffers.
Receives the stored BuildContext. Implementations must use config.allocationSeqLen() when sizing output buffers — this is the single call that makes Inference and Training allocate the correct buffer sizes automatically without per-component logic.
The default implementation forwards to the legacy onBuilding( const shape_t& ) overload for backwards compatibility. New components should override this overload directly.
- Note
- Do not call build() or onBuilding() from within this hook.
- Implementations should either succeed fully or leave no partial state, as a failed build() may be retried.
- Parameters
-
config Build-time configuration. Use config.allocationSeqLen() to obtain the correct output buffer sequence dimension.
Reimplemented from Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ onTrainingModeChanging()
|
inlineoverrideexportprotectedvirtual |
Hook invoked when training mode is about to change.
Propagates the new mode to all child components. The hook runs with the Component's training mutex held; it MUST NOT call setTraining().
- Parameters
-
is_training New training mode (true = training, false = eval)
Reimplemented from Mila::Dnn::CompositeComponent< TDeviceType, TPrecision >.
◆ resetKVCache()
|
inlineexport |
Reset KV cache state on the contained Attention component.
Intended to be called exclusively by the owning transformer's generate() between independent generation requests.
◆ save_()
|
inlineoverrideexportvirtual |
Save all child components recursively.
Follows the component serialization contract:
- Writes type, version, and configuration metadata
- Recursively saves all children with scoped namespaces
- Each child's save_() handles its own state
- Parameters
-
archive Archive to write to mode What to save (Checkpoint, WeightsOnly, Architecture)
Reimplemented from Mila::Dnn::CompositeComponent< TDeviceType, TPrecision >.
◆ supportsKVCache()
|
inlineexportnoexcept |
Returns true when the contained Attention supports KV caching.
Propagates the capability query up from Attention without exposing IKVCacheable directly. GptTransformer uses this to decide whether generate() can take the fast decode path.

◆ toString()
|
inlineoverrideexportvirtual |
Generate a human-readable description.
- Returns
- String representation showing children
Reimplemented from Mila::Dnn::CompositeComponent< TDeviceType, TPrecision >.
◆ validateBuildContext()
|
inlineexportprivate |


◆ validateInputShape()
|
inlineexportprivate |
◆ zeroGradients()
|
inlineoverrideexportvirtual |
Clear all model-owned gradients for this component.
Default implementation is a no-op. Composite components should override to recurse to children. Leaf components should override to zero their parameter and activation gradients using device-aware helpers.
Reimplemented from Mila::Dnn::Component< TDeviceType, TPrecision >.

The documentation for this class was generated from the following file:
- /__w/Mila/Mila/Mila/Src/Dnn/Components/Transformers/Gpt/GptBlock.ixx