Multi-Head Attention module that accepts concatenated QKV input. More...

Public Types | |
| using | ComponentBase = Component<TDeviceType, TPrecision> |
| using | MR = typename DeviceTypeTraits<TDeviceType>::memory_resource |
| using | TensorType = Tensor<TPrecision, MR> |
Public Member Functions | |
| MultiHeadAttention (const std::string &name, const MultiHeadAttentionConfig &config, std::optional< DeviceId > device_id=std::nullopt) | |
| Construct MultiHeadAttention component. | |
| ~MultiHeadAttention () override=default | |
| TensorType & | backward (const TensorType &input, const TensorType &output_grad) |
| Run backward pass and return component-owned input-gradient tensor. | |
| TensorType & | decode (const TensorType &input, int position) |
| Inference-only single-token decode pass. | |
| TensorType & | forward (const TensorType &input) |
| Standard forward pass. | |
| const MultiHeadAttentionConfig & | getConfig () const noexcept |
| DeviceId | getDeviceId () const override |
| Get the compute device id associated with this component. | |
| std::vector< ITensor * > | getGradients () const override |
| Return non-owning pointers to parameter gradient tensors. | |
| MemoryStats | getMemoryStats () const override |
| Return the current memory allocation breakdown for this component. | |
| int64_t | getModelDim () const noexcept |
| int64_t | getNumHeads () const noexcept |
| std::vector< ITensor * > | getParameters () const override |
| Return non-owning pointers to parameter tensors. | |
| const ComponentType | getType () const override |
| Get the component type identifier. | |
| size_t | parameterCount () const override |
| Return number of trainable parameters. | |
| void | save_ (ModelArchive &archive, SerializationMode mode) const override |
| bool | supportsKVCache () const noexcept |
| Returns true when the underlying operation implements both IPositionalUnaryOp and IKVCacheLifecycle. | |
| void | synchronize () override |
| Wait for outstanding device work submitted by this component. | |
| std::string | toString () const override |
| Produce a short, human-readable description of the component. | |
| Public Member Functions inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| Component (const std::string &name) | |
| Construct component with required name identifier. | |
| virtual | ~Component ()=default |
| virtual void | build (const BuildContext &context) final |
| Build the component with the provided BuildContext (canonical overload). | |
| const std::string | getName () const |
| Get the component's name identifier. | |
| virtual std::vector< std::string > | getParameterNames () const |
| List all available parameter names for this component. | |
| RuntimeMode | getRuntimeMode () const noexcept |
| Convenience accessor — true if currently in Eval mode. | |
| TrainingMode | getTrainingMode () const noexcept |
| The current runtime behavioral mode of this Component. | |
| virtual bool | isBuilt () const final |
| Returns true if build() has completed successfully. | |
| bool | isInferenceMode () const noexcept |
| bool | isTrainingMode () const noexcept |
| virtual void | loadParameter (const std::string &name, const Serialization::ITensorBlob &blob) |
| Load a parameter from serialized tensor data. | |
| void | setTrainingMode (TrainingMode mode) |
| Set the runtime behavioral mode for this Component. | |
| virtual void | zeroGradients () |
| Clear all model-owned gradients for this component. | |
Protected Member Functions | |
| void | onBuilding (const BuildContext &build_config) override |
| Hook invoked by build() to allocate component buffers. | |
| void | onExecutionContextSet () override |
| Lifecycle hook: Called immediately after ExecutionContext is set. | |
| void | onTrainingModeChanging (TrainingMode training_mode) override |
| Hook called before TrainingMode transitions. | |
| Protected Member Functions inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| IExecutionContext * | getExecutionContext () const |
| Get the shared execution context. | |
| bool | hasExecutionContext () const noexcept |
| Check if execution context has been set. | |
| template<TensorDataType TParameterPrecision, typename TMemoryResource> | |
| void | loadParameterFromBlob (const std::string ¶m_name, const Serialization::ITensorBlob &blob, Tensor< TParameterPrecision, TMemoryResource > &target, const shape_t &expected_shape) |
| Load a tensor blob into a parameter tensor with validation. | |
| void | setExecutionContext (IExecutionContext *context) |
| Set the execution context for this component. | |
Private Types | |
| using | OpType = typename OperationTraits<OperationType::MultiHeadAttentionOp, TDeviceType, TPrecision>::type |
Private Member Functions | |
| void | createOperation () |
| TensorType & | resolveOutputView (const shape_t &input_shape) |
| void | validateConcatenatedQKVShape (const shape_t &shape) const |
Private Attributes | |
| bool | cache_initialized_ { false } |
| MultiHeadAttentionConfig | config_ |
| std::unique_ptr< IExecutionContext > | context_ { nullptr } |
| bool | decode_active_ { false } |
| IKvCacheLifecycle * | kv_cache_op_ { nullptr } |
| shape_t | max_input_shape_ |
| std::shared_ptr< OpType > | operation_ { nullptr } |
| std::unique_ptr< TensorType > | output_view_ { nullptr } |
| std::unique_ptr< TensorType > | owned_decode_output_ { nullptr } |
| std::unique_ptr< TensorType > | owned_input_grad_ { nullptr } |
| std::unique_ptr< TensorType > | owned_output_ { nullptr } |
| IPackedKvInference * | positional_op_ { nullptr } |
Additional Inherited Members | |
| Static Public Member Functions inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| static constexpr DeviceType | getDeviceType () |
| Compile-time device type for this component instance. | |
| static constexpr TensorDataType | getPrecision () noexcept |
| Compile-time tensor precision for this component instance. | |
| Protected Attributes inherited from Mila::Dnn::Component< TDeviceType, TPrecision > | |
| BuildContext | build_context_ { shape_t{ 1 }, RuntimeMode::Training } |
| The BuildContext stored at build time. | |
Detailed Description
requires PrecisionSupportedOnDevice<TPrecision, TDeviceType>
class Mila::Dnn::MultiHeadAttention< TDeviceType, TPrecision >
Multi-Head Attention module that accepts concatenated QKV input.
The module requires a single input tensor in model-layout containing concatenated Q, K and V along the feature axis: input shape == [B, T, 3 * embedding_dim]
The backend compute implementation (registered as "MultiHeadAttentionOp") must accept the concatenated QKV input and produce an output of shape: output shape == [B, T, embedding_dim]
KV-cache inference is an optional backend capability. After build(), supportsKVCache() indicates whether the underlying operation implements both IPositionalUnaryOp (prefill/decode dispatch) and IKVCacheLifecycle (cache init/reset). Both pointers are resolved once at build time.
The KV cache lifecycle (initializeKVCache / resetKVCache) is intended to be driven exclusively by the owning transformer's generate() method. forward() is the sole entry point for prefill; decode() handles autoregressive single-token generation.
REVIEW: initializeKVCache() and resetKVCache() are currently public. When TransformerBase<> is introduced as the common base for GptTransformer, LlamaTransformer, MistralTransformer etc., revisit whether these should become private with 'friend class TransformerBase<TDeviceType, TPrecision>' to enforce that only the generate() orchestration path may manage the KV cache lifecycle.
Constructor & Destructor Documentation
◆ MultiHeadAttention()
|
inlineexplicitexport |
Construct MultiHeadAttention component.
- Parameters
-
name Component name identifier (mandatory). config MultiHeadAttention configuration. device_id Optional DeviceId to create owned ExecutionContext (standalone mode).

◆ ~MultiHeadAttention()
|
overrideexportdefault |
Member Function Documentation
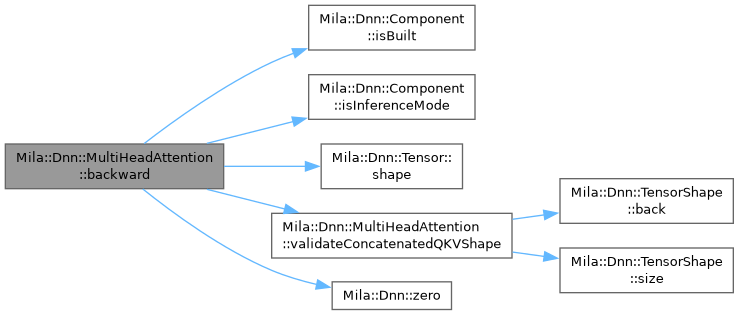
◆ backward()
|
inlineexport |
Run backward pass and return component-owned input-gradient tensor.
- Parameters
-
input Concatenated QKV input tensor used in forward. output_grad Gradient w.r.t. the module output.
- Returns
- Reference to component-owned TensorType containing the input gradient.
◆ createOperation()
|
inlineexportprivate |


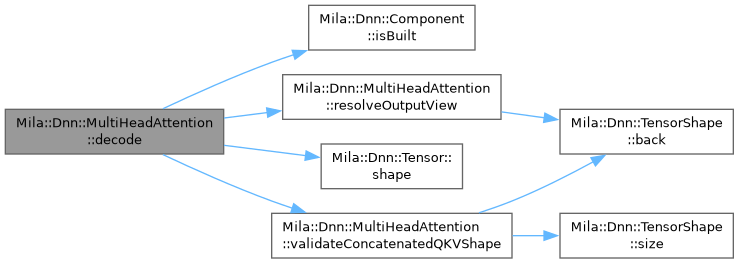
◆ decode()
|
inlineexport |
Inference-only single-token decode pass.
When the backend implements IPositionalUnaryOp and the cache has been populated by a prior forward() call, uses the fast O(n) KV cache path. When the backend does not support positional dispatch (CpuMultiHeadAttentionOp), falls back to forward(). The caller never needs to know which path was taken.
Precondition: forward() must have been called at least once to populate the KV cache before decode() is called.
- Parameters
-
input Single-token QKV input [B, 1, 3 * embedding_dim]. position Current sequence position (0-based).
- Returns
- Reference to component-owned single-token output tensor.
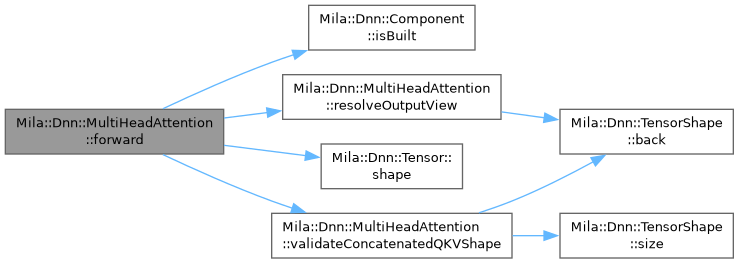
◆ forward()
|
inlineexport |
Standard forward pass.
Always available regardless of backend. When the backend supports KV caching, the first forward() call initializes and populates the cache (prefill with position_offset=0). When called again after decode() steps, it automatically resets the cache and begins a new prefill session — no explicit session management required by callers.
- Parameters
-
input Concatenated QKV input [B, T, 3 * embedding_dim].
- Returns
- Reference to component-owned output tensor.
◆ getConfig()
|
inlineexportnoexcept |
◆ getDeviceId()
|
inlineoverrideexportvirtual |
Get the compute device id associated with this component.
Must return the device on which parameters and operations execute.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.

◆ getGradients()
|
inlineoverrideexportvirtual |
Return non-owning pointers to parameter gradient tensors.
Only valid when isTraining() is true.
- Exceptions
-
std::runtime_error if called when not in training mode or before the component has been built.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ getMemoryStats()
|
inlineoverrideexportvirtual |
Return the current memory allocation breakdown for this component.
Reflects allocations at the moment of the call. The returned stats naturally track the component lifecycle:
After construction — parameters only After build( Inference ) — parameters + T=1 state buffers After build( Training ) — parameters + T=full state buffers After setEvaluation( false ) — parameters + state + gradients
For CompositeComponent and Network, the returned stats are the recursive aggregate of all child components.
May be called at any time — no lifecycle preconditions.
- Returns
- MemoryStats reflecting current allocations.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ getModelDim()
|
inlineexportnoexcept |
◆ getNumHeads()
|
inlineexportnoexcept |
◆ getParameters()
|
inlineoverrideexportvirtual |
Return non-owning pointers to parameter tensors.
The returned tensor pointers remain valid for the lifetime of the component. Order should be canonical (weights before biases).
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ getType()
|
inlineoverrideexportvirtual |
Get the component type identifier.
Used for serialization and runtime type identification.
- Returns
- Component type enum value.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ onBuilding()
|
inlineoverrideexportprotectedvirtual |
Hook invoked by build() to allocate component buffers.
Receives the stored BuildContext. Implementations must use config.allocationSeqLen() when sizing output buffers — this is the single call that makes Inference and Training allocate the correct buffer sizes automatically without per-component logic.
The default implementation forwards to the legacy onBuilding( const shape_t& ) overload for backwards compatibility. New components should override this overload directly.
- Note
- Do not call build() or onBuilding() from within this hook.
- Implementations should either succeed fully or leave no partial state, as a failed build() may be retried.
- Parameters
-
config Build-time configuration. Use config.allocationSeqLen() to obtain the correct output buffer sequence dimension.
Reimplemented from Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ onExecutionContextSet()
|
inlineoverrideexportprotectedvirtual |
Lifecycle hook: Called immediately after ExecutionContext is set.
Override this to perform initialization that requires a valid ExecutionContext. At the time this is called, getExecutionContext() is guaranteed to return a valid context.
Common uses:
- Composite components: Create and configure child components.
- Device resource allocation: Query device capabilities.
Default implementation does nothing.
- Exceptions
-
Any exception thrown will cause setExecutionContext() to fail and restore the component to a "context not set" state.
Reimplemented from Mila::Dnn::Component< TDeviceType, TPrecision >.

◆ onTrainingModeChanging()
|
inlineoverrideexportprotectedvirtual |
Hook called before TrainingMode transitions.
Called by setTrainingMode() after validation and lock acquisition, before the internal state is updated. Derived classes override to respond to the transition — e.g. zeroing gradient buffers on transition to Eval, or re-enabling dropout on transition to Training.
The default implementation is a no-op.
- Parameters
-
mode The incoming TrainingMode.
Reimplemented from Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ parameterCount()
|
inlineoverrideexportvirtual |
Return number of trainable parameters.
For leaf components this is the element count of owned parameter tensors. CompositeComponent and Network implementations should return the recursive aggregate across all children.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.

◆ resolveOutputView()
|
inlineexportprivate |

◆ save_()
|
inlineoverrideexportvirtual |
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ supportsKVCache()
|
inlineexportnoexcept |
Returns true when the underlying operation implements both IPositionalUnaryOp and IKVCacheLifecycle.
Resolved once at build time. CPU backends return false; CUDA backends return true when CudaMultiHeadAttentionOp is in use. Safe to query before calling generate() to determine which forward path is available.

◆ synchronize()
|
inlineoverrideexportvirtual |
Wait for outstanding device work submitted by this component.
On CPU this may be a no-op. Use to ensure results are visible to the host or to measure synchronous timings.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.

◆ toString()
|
inlineoverrideexportvirtual |
Produce a short, human-readable description of the component.
Implementations should keep output concise and avoid throwing.
Implements Mila::Dnn::Component< TDeviceType, TPrecision >.
◆ validateConcatenatedQKVShape()
|
inlineexportprivate |
The documentation for this class was generated from the following file:
- /__w/Mila/Mila/Mila/Src/Dnn/Components/Attention/MHA/MultiHeadAttention.ixx